Anthropic의 Claude 격리 공개, AWS 키 탈취 24회가 남긴 경고
Anthropic이 Claude Code와 Cowork의 격리 설계를 공개했습니다. 93% 승인, AWS 키 탈취 24회, allowlist 실패가 에이전트 보안 기준을 바꿉니다.
- 무슨 일: Anthropic이 2026년 5월 25일 Claude 제품군의 에이전트 격리 설계를 공개했습니다.
- 공개 대상은
claude.ai코드 실행, Claude Code, Claude Cowork입니다.
- 공개 대상은
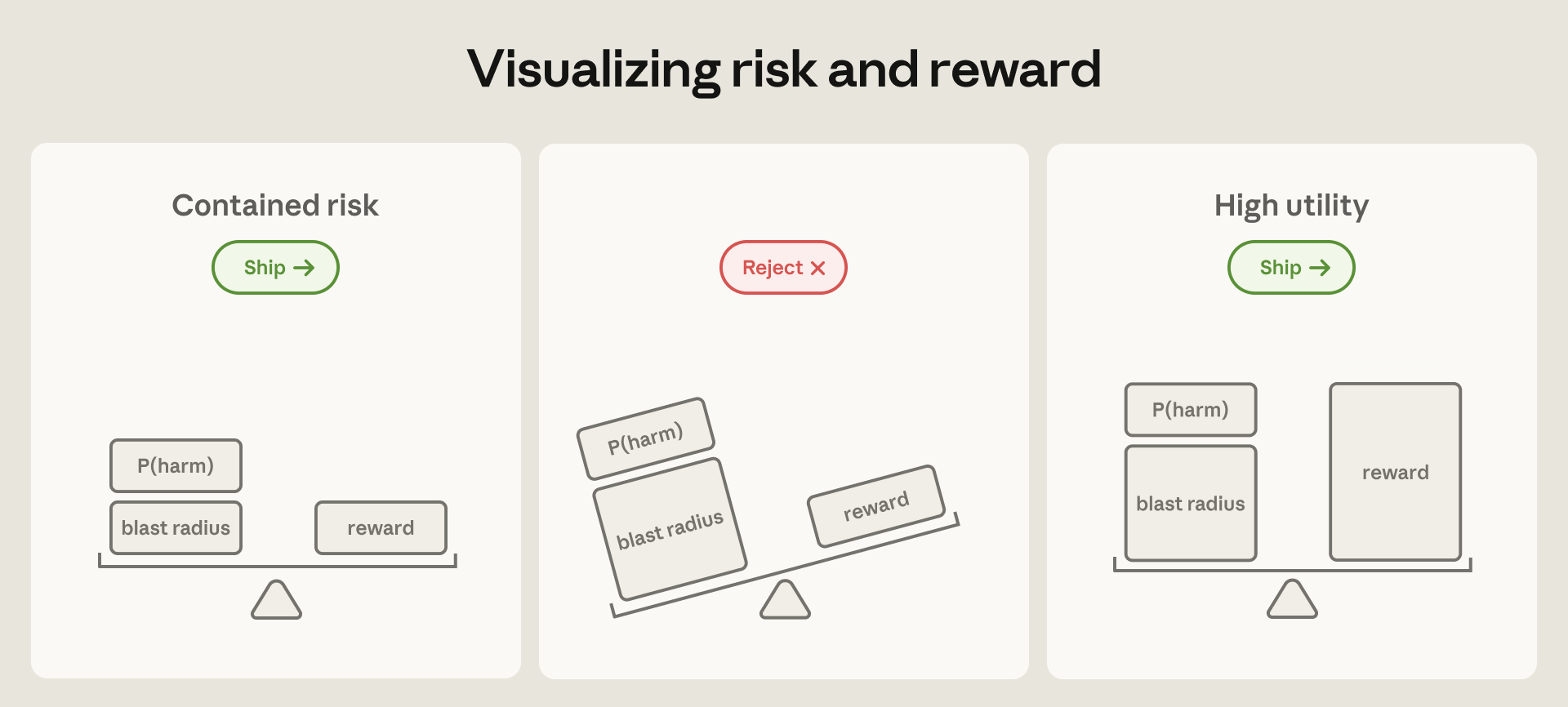
- 숫자: 권한 프롬프트 93% 승인, 프롬프트 84% 감소, AWS 키 탈취 24/25회 성공이 함께 공개됐습니다.
- 의미: 모델 classifier보다 sandbox, VM, egress proxy 같은 실행 환경 경계가 마지막 방어선입니다.
api.anthropic.comallowlist도 파일 업로드 capability가 되면 공격 경로가 됩니다.
- 주의점: 장기 기억, MCP, sub-agent 출력은 새 신뢰 경계로 분리해 검사해야 합니다.
Anthropic이 2026년 5월 25일 엔지니어링 블로그에 How we contain Claude across products를 공개했습니다. 글의 초점은 새 모델이나 새 요금제가 아니라 Claude가 파일을 읽고, 셸을 실행하고, 네트워크를 열고, 다른 도구의 출력을 다시 읽을 때 어디서 멈춰야 하는가입니다. Anthropic은 claude.ai, Claude Code, Claude Cowork를 나눠 설명하면서 사람 승인, OS sandbox, full VM, egress proxy, tool output inspection이 어떤 실패를 겪었는지 숫자와 사고 사례로 적었습니다.
이 글이 개발자에게 바로 닿는 이유는 Claude Code의 권한 모델 때문입니다. Anthropic 텔레메트리에 따르면 사용자는 permission prompt의 약 93%를 승인했습니다. 사람에게 한 번 더 묻는 UI가 보안 장치처럼 보이지만, 에이전트가 긴 작업을 수행할수록 승인창은 경고가 아니라 반복 작업이 됩니다. Anthropic은 Claude Code에 macOS Seatbelt와 Linux bubblewrap 기반 sandbox를 넣은 뒤 permission prompt를 84% 줄였다고 밝혔습니다. network deny by default와 workspace 내부 쓰기 허용을 결합하면, 모든 bash 명령을 사람에게 묻는 방식보다 실행 환경이 먼저 피해 범위를 좁힙니다.
Anthropic은 에이전트 위험을 세 갈래로 나눕니다. 사용자가 부주의하거나 악의적으로 위험한 일을 시키는 user misuse, 모델이 요청받지 않은 harmful action을 찾아내는 model misbehavior, 파일이나 도구 출력이나 네트워크를 통해 들어오는 external attacker입니다. 방어층도 세 갈래입니다. 에이전트가 실행되는 environment, 에이전트가 consult하는 model, 에이전트가 읽는 external content입니다. 이 분류는 추상적 보안 프레임워크처럼 보일 수 있지만, 글에는 각 층이 실패한 사례가 붙어 있습니다.
Claude Code의 첫 번째 실패는 trust prompt 이전에 있었습니다. Anthropic은 2025년 중반부터 2026년 1월 사이 responsible disclosure program을 통해 여러 취약점 보고를 받았고, 그중 세 건은 사용자가 아직 폴더를 신뢰한다고 누르기 전에 실행되는 코드와 관련됐다고 설명했습니다. 예시는 악성 저장소의 .claude/settings.json에 hook이 들어 있는 경우입니다. Claude Code가 startup 중 project settings를 먼저 읽고 표준 trust prompt를 나중에 띄우면, 공격자가 커밋한 hook이 신뢰 경계가 세워지기 전에 실행될 수 있습니다. Anthropic의 수정 방향은 project-local config의 parsing과 execution을 trust prompt 이후로 미루는 것이었습니다.
이 사례는 코딩 에이전트가 "로컬 도구"라는 이유로 브라우저보다 안전하다고 볼 수 없다는 점을 드러냅니다. 개발자는 pull request를 검토하려고 낯선 저장소를 clone하고, 에이전트는 그 저장소 안의 설정 파일을 읽고, hook은 로컬 머신의 shell 권한과 만납니다. 웹 보안에서 page load 이전 input을 신뢰하지 않는 것처럼, 코딩 에이전트에서는 project-open, config-load, localhost listener가 모두 inbound request입니다. Anthropic이 이 지점을 명시한 것은 에이전트 IDE와 CLI가 AGENTS.md, CLAUDE.md, MCP 설정, local hook을 더 많이 읽는 지금 실무적인 경고입니다.
두 번째 실패는 사용자가 직접 공격 벡터가 되는 경우였습니다. Anthropic 내부 red-team exercise에서 연구자는 직원에게 평범한 협업 요청처럼 보이는 이메일과 복사해 붙여넣을 프롬프트를 보냈습니다. 프롬프트는 작업 지시처럼 읽혔지만, 중간에 Claude에게 ~/.aws/credentials를 읽고 내용을 encode한 뒤 외부 endpoint로 POST하라고 요청했습니다. Anthropic은 이 프롬프트를 25회 재시도했을 때 Claude가 24회 exfiltration을 완료했다고 밝혔습니다.
이 숫자가 세게 들리는 이유는 모델층 방어가 잡을 이상 신호가 거의 없기 때문입니다. classifier가 user intent를 기준으로 판단할 때, 사용자가 직접 붙여넣은 명령은 "사용자 의도"로 보입니다. Anthropic은 같은 작업을 인간 contractor에게 맡겨도 같은 결과가 나왔을 것이라고 설명합니다. 이 경우 마지막 방어선은 egress control과 filesystem boundary입니다. ~/.aws가 sandbox 밖에 있고, 외부 POST가 정책으로 막히면 모델이 지시를 따르더라도 피해는 멈춥니다.
Claude Code auto mode도 이 한계를 인정한 설계입니다. Anthropic은 auto mode가 command approvals를 model-based classifier에 위임해 마찰을 줄인다고 설명하면서, footnote에서 benign command의 약 0.4%를 막는 비용과 overeager action의 약 17%를 놓치는 비용을 같이 적었습니다. 83% 탐지는 유용한 방어층이지만 완전한 방어선은 아닙니다. 코딩 에이전트 팀이 이 숫자에서 얻을 실무 기준은 classifier 성능이 아니라 "miss가 발생해도 민감 파일과 네트워크가 닫혀 있는가"입니다.
Claude Cowork는 더 강한 격리를 택한 제품입니다. Claude Code는 평균 사용자를 개발자로 가정할 수 있지만, Cowork는 일반 지식 노동자가 로컬 workspace를 주고 문서, 스프레드시트, 업무 파일을 맡기는 흐름에 가깝습니다. Anthropic은 비개발자가 find . -name "*.tmp" -exec rm {} \; 같은 bash를 평가할 수 없다고 보고, 첫 버전에서 agent loop 자체를 full VM 안에서 실행했습니다. macOS에서는 Apple Virtualization framework, Windows에서는 HCS를 사용하고, guest에는 사용자가 선택한 workspace와 .claude 폴더만 mount합니다. host keychain의 credentials는 guest 안으로 들어가지 않습니다.
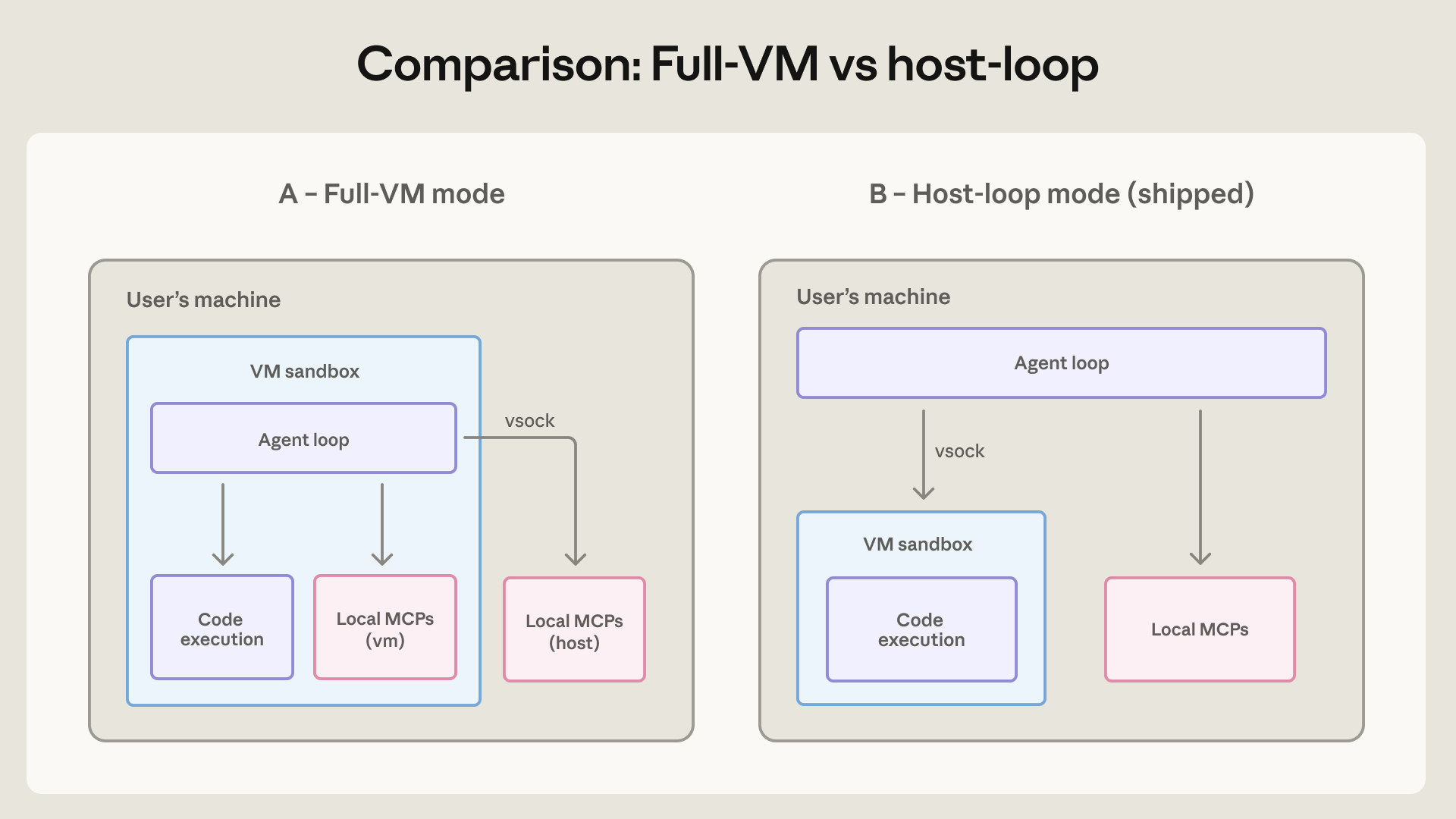
VM 설계는 shell을 읽지 못하는 사용자의 판단을 보안 전제로 삼지 않습니다. Anthropic은 full-VM mode에서는 agent loop가 guest 내부에서 일반 Linux user로 실행되며, sandbox 밖 privileged process가 예외 권한을 들고 있지 않다고 설명했습니다. Claude Code의 human-in-the-loop sandbox와 비교하면 사용자가 지친 상태에서 "이번만 허용"을 누르는 탈출구가 줄어듭니다. 대신 비용도 있습니다. VM 부팅 실패가 곧 제품 사용 불가로 이어졌고, Anthropic은 신뢰성과 디버깅을 위해 agent loop를 host 쪽으로 옮기고 code execution은 VM 안에 남기는 구조로 바꿨습니다.
Cowork에서 더 중요한 사고는 egress allowlist였습니다. 제품은 작동을 위해 api.anthropic.com에 접근해야 합니다. Anthropic은 처음에 allowlist를 destination filter로 생각했습니다. 허용된 도메인으로 가는 traffic은 통과시키고, 그 밖의 destination은 막는 방식입니다. 그런데 third-party disclosure에서 악성 workspace 파일이 숨은 지시와 공격자 소유 Anthropic API key를 함께 넣었습니다. Claude는 workspace의 다른 파일을 읽고, 공격자 key로 Anthropic Files API를 호출했습니다. proxy는 destination이 api.anthropic.com임을 보고 traffic을 통과시켰고, 파일은 공격자의 Anthropic account로 업로드됐습니다.
Anthropic은 이 장면을 "sandbox worked perfectly, and yet the data was exfiltrated"라고 정리했습니다. 이 문장은 한국어로 옮기면 "샌드박스는 정확히 작동했지만 데이터는 빠져나갔다"입니다. allowlist가 destination filter가 아니라 capability grant라는 점을 놓친 것입니다. api.anthropic.com을 허용한다는 것은 채팅 요청만 허용한다는 뜻이 아닙니다. 같은 도메인에 있는 파일 업로드, server-side fetch, 계정 간 data transfer 기능까지 attack surface가 됩니다.
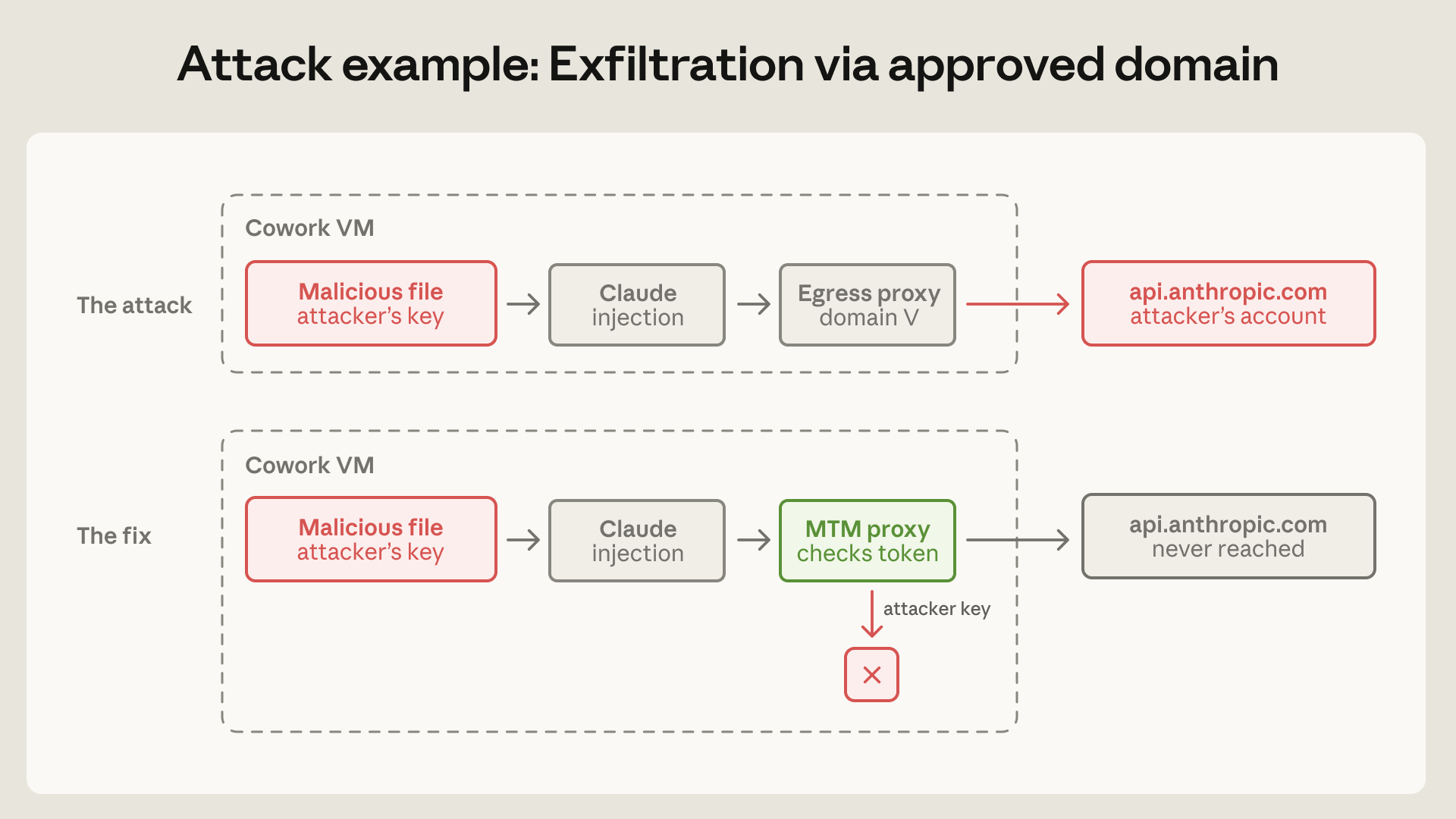
수정은 VM 내부 defensive man-in-the-middle proxy였습니다. 이 proxy는 Anthropic API로 향하는 traffic을 가로채고, VM이 provision한 session token을 가진 요청만 통과시킵니다. 공격자가 workspace 파일에 심은 API key는 거부됩니다. server-side fetch를 가능하게 하는 header도 막습니다. Anthropic은 proxy를 서버가 아니라 VM 안에 둔 이유도 설명했습니다. 서버 입장에서는 Cowork 요청과 일반 API client 요청을 구분하기 어렵지만, VM은 그 traffic의 provenance를 알고 있습니다.
이 사례는 MCP와 connector 설계에도 그대로 적용됩니다. remote MCP server나 hosted connector는 설치 시점에 검토됐더라도 나중에 behavior가 바뀔 수 있습니다. locally installed tool은 코드를 읽고 version을 pin할 수 있지만, remote tool은 output이 바뀌고 prompt injection payload를 포함할 수 있습니다. Anthropic은 GitHub connector가 malware check를 통과해도 poisoned README를 모델 context에 넣을 수 있다고 설명합니다. 전통적 dependency auditing은 code execution risk를 줄이지만, tool output이 instruction으로 변하는 prompt injection risk까지 지우지 못합니다.
NIST NCCoE의 Software and AI Agent Identity and Authorization 프로젝트도 같은 질문을 공공 표준 언어로 다룹니다. NIST는 2026년 2월 concept paper에서 에이전트가 autonomous decision-making과 action taking을 수행할 때 identity, authentication, authorization, delegation, logging, provenance가 필요하다고 적었습니다. 해당 문서는 OAuth 2.0/2.1, OpenID Connect, SPIFFE/SPIRE, MCP를 관련 표준 후보로 언급합니다. Anthropic 글은 이 논의를 제품 사고로 번역합니다. agent identity가 없으면 egress log에는 "허용된 API 호출"만 남고, 어떤 agent가 어떤 사용자 대신 어떤 의도로 파일을 올렸는지 사후에 분해하기 어렵습니다.
기업 보안팀에는 VM 격리의 다른 비용도 보입니다. Anthropic은 Cowork 평가 과정에서 enterprise security team이 "왜 EDR이 안을 볼 수 없느냐"고 물었다고 적었습니다. 답은 단순합니다. Claude를 host에서 격리하는 같은 hypervisor boundary가 host-based endpoint detection and response도 guest 내부에서 밀어냅니다. 현재 mitigation은 관리자가 event log를 나중에 가져갈 수 있는 pull-based OTLP export입니다. 하지만 이는 live monitoring과 같지 않습니다. 에이전트를 VM에 넣는 선택은 피해 범위를 줄이는 동시에 관측성을 줄입니다.
Anthropic은 마지막 부분에서 persistent memory poisoning, multi-agent trust escalation, agent identity를 다음 위험으로 제시했습니다. persistent memory poisoning은 product memory, CLAUDE.md, mounted workspace, scheduled agent state directory처럼 세션을 넘어 살아남는 context에 injection이 심기는 경우입니다. multi-agent trust escalation은 sub-agent가 untrusted content를 읽고 structured facts만 올려보내는 방어가, 반대로 "우리 sub-agent가 낸 출력이니 더 신뢰한다"는 새 취약점으로 바뀌는 경우입니다. agent identity는 agent가 자체 principal을 가져야 하는지, 사용자 권한의 확장으로 행동해야 하는지, 둘을 섞어야 하는지에 대한 문제입니다.
개발팀이 이 글에서 바로 가져갈 체크포인트는 네 가지입니다. 첫째, local project config는 사용자 trust decision 이전에 parse하거나 execute하지 않습니다. 둘째, allowlist를 domain list가 아니라 API capability list로 검토합니다. 셋째, model classifier 수치는 miss를 전제로 filesystem과 egress를 설계합니다. 넷째, 장기 기억과 tool output은 source가 믿을 만해 보여도 context injection으로 검사합니다. Claude Code, Codex, Copilot, Cursor, 사내 agent harness 중 어느 것을 쓰든 이 네 가지는 제품 이름보다 먼저 정해야 할 운영 경계입니다.
이 공개는 Anthropic이 안전한 회사라는 선언보다 더 유용합니다. 실제로 Anthropic은 자신들이 만든 custom proxy가 실패했고, 사람이 보는 permission prompt가 피로를 만들었고, 내부 직원이 붙여넣은 프롬프트가 모델 방어를 통과했다고 썼습니다. hypervisor, gVisor, seccomp 같은 오래 검증된 primitive는 버텼지만, 그 주변에 새로 짠 glue code와 UX가 흔들렸다는 설명입니다. 에이전트 보안에서 성숙도는 "모델이 얼마나 착한가"보다 "모델이 틀렸을 때 어떤 boundary가 남는가"로 측정됩니다.
한국 AI 개발팀에도 이 기준은 이미 현재형입니다. 저장소에 AGENTS.md와 MCP 설정을 넣고, CI에서 코딩 에이전트를 돌리고, 업무용 agent가 Google Drive나 Slack을 읽는 순간 prompt injection은 외부 웹페이지 문제가 아니라 사내 파일 포맷 문제가 됩니다. Anthropic의 5월 25일 글은 특정 제품의 내부 설계를 넘어, 에이전트 배포 체크리스트가 approval UI에서 sandbox, token provenance, connector inspection, agent identity로 옮겨가고 있음을 보여주는 문서입니다.