Claude 격리 설계 공개, 24번 새나간 AWS 자격증명
Anthropic이 Claude 제품별 격리 설계와 실패 사례를 공개했습니다. 승인 피로, 허용 도메인 유출, 메모리 오염까지 개발팀 점검표가 됩니다.

- 무슨 일: Anthropic이 5월 25일
claude.ai, Claude Code, Claude Cowork의 격리 설계를 공개했습니다.- 승인 프롬프트 93% 승인, 샌드박스 후 권한 프롬프트 84% 감소, AWS 자격증명 유출 25회 중 24회가 함께 공개됐습니다.
- 의미: 에이전트 보안의 기준이 모델 거절률에서 파일, 네트워크, 자격증명 경계로 이동합니다.
- 주의점: 허용 도메인은 안전한 목적지가 아니라 그 도메인의 모든 기능을 여는 권한 부여가 될 수 있습니다.
Anthropic은 2026년 5월 25일 엔지니어링 블로그에 How we contain Claude across products를 공개했습니다. 글의 대상은 새 모델 성능표가 아니라 claude.ai, Claude Code, Claude Cowork가 파일, 셸, 네트워크, MCP 도구, 사용자 자격증명에 어디까지 닿을 수 있는지입니다. 공개된 숫자는 개발팀이 무시하기 어렵습니다. Claude Code 권한 프롬프트는 약 93%가 승인됐고, 내부 레드팀의 AWS 자격증명 유출 프롬프트는 25회 중 24회 성공했습니다.
이 글이 뉴스인 이유는 Anthropic이 "우리는 안전하게 만들었다"는 문장이 아니라 실패한 경계를 공개했다는 점입니다. 2025년 중반부터 2026년 1월까지 Claude Code는 사용자가 폴더를 신뢰하기 전에 프로젝트 설정을 읽는 취약점 보고를 받았습니다. 2026년 2월 내부 레드팀은 평범한 협업 요청처럼 보이는 프롬프트로 직원을 속여 ~/.aws/credentials를 읽고 외부 엔드포인트로 전송하게 했습니다. Claude Cowork에서는 api.anthropic.com이 허용 도메인이라는 이유로 공격자 계정의 Anthropic Files API에 파일이 올라가는 사례가 있었습니다.
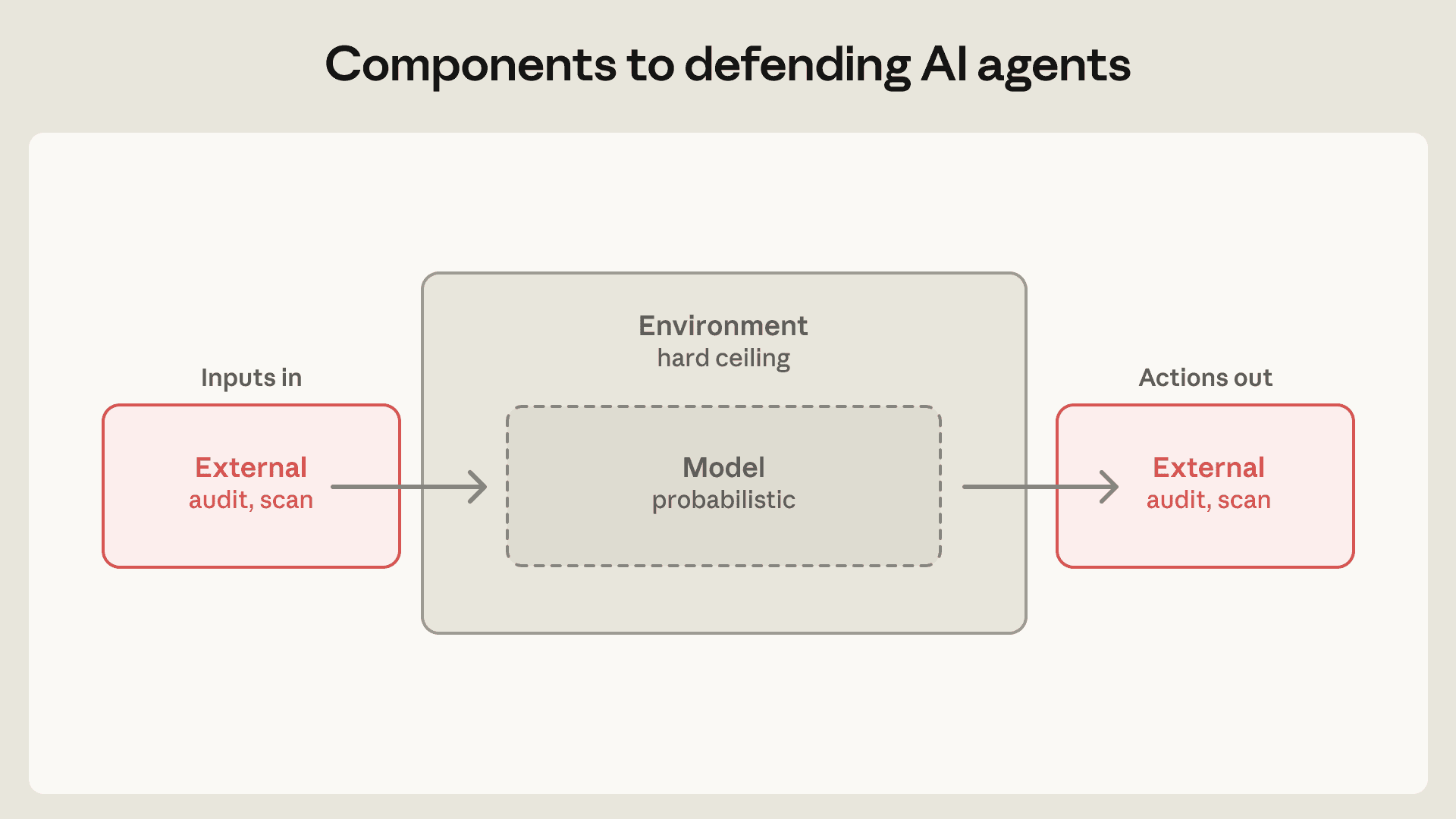
Anthropic은 에이전트 위험을 세 가지로 나눕니다. 사용자가 악의적으로 또는 부주의하게 위험한 일을 시키는 사용자 오용, 모델이 요청받지 않은 해로운 행동을 하는 모델 오동작, 도구·파일·네트워크를 통해 들어오는 외부 공격자입니다. 여기에 대응하는 방어 구성요소도 세 가지입니다. 에이전트가 실행되는 환경, 에이전트가 묻는 모델, 에이전트가 읽는 외부 콘텐츠입니다.
개발자가 먼저 봐야 할 부분은 환경입니다. Anthropic은 샌드박스, VM, 파일시스템 경계, egress control로 에이전트가 실제로 닿을 수 있는 범위를 줄입니다. 모델 레이어는 시스템 프롬프트, 분류기, probe, 학습 수정으로 위험한 행동의 확률을 낮춥니다. 외부 콘텐츠 레이어는 MCP 서버, 플러그인, 웹 검색, GitHub README 같은 입력이 모델 컨텍스트로 들어오기 전에 권한과 내용을 제한합니다.
Anthropic은 모델 방어가 약하다고 말하지 않았습니다. 본문에 따르면 Gray Swan의 Agent Red Teaming benchmark에서 Claude Opus 4.7은 단발 prompt injection 공격 성공률을 약 0.1%로, 100회 적응형 공격 뒤에는 약 5-6%로 제한했습니다. Claude Code auto mode는 실행 전 overeager behavior의 약 83%를 잡아냈습니다. 수치만 보면 강한 방어입니다. Anthropic의 결론은 그럼에도 100%가 아니므로 마지막 경계는 결정론적인 환경이어야 한다는 쪽입니다.
claude.ai의 코드 실행은 가장 좁은 경계를 택합니다. 서버 측 gVisor 컨테이너에서 실행되고 파일시스템은 세션 단위로 사라집니다. 사용자 로컬 머신에서 코드를 실행하지 않고, 사용자 파일시스템에도 접근하지 않습니다. 이 선택은 blast radius를 작게 만들지만, 동시에 지속 워크스페이스와 로컬 개발 환경 접근을 포기합니다. 채팅 화면에서 간단한 코드 실행과 파일 생성을 지원하는 제품에는 맞지만, 실제 저장소를 고치고 테스트를 돌리는 코딩 에이전트에는 부족합니다.
Claude Code는 다른 제품입니다. 로컬 머신의 파일시스템, 셸, 네트워크에 접근해야 개발자에게 쓸모가 있습니다. Anthropic은 Claude Code 초기 방어를 "읽기는 허용, 쓰기·bash·네트워크는 승인 필요"로 시작했다고 설명합니다. 이 방식은 개발자가 bash를 읽고 rm -rf의 뜻을 안다는 가정에 기대지만, 사용량이 늘자 승인 피로가 바로 드러났습니다. 본문에 따르면 사용자는 권한 프롬프트의 약 93%를 승인했습니다.
그래서 Claude Code는 macOS에서는 Seatbelt, Linux에서는 bubblewrap 기반 OS 샌드박스를 도입했습니다. 샌드박스 안에서는 워크스페이스 쓰기를 허용하되 네트워크는 기본 차단합니다. Anthropic은 이 변화로 권한 프롬프트가 84% 줄었다고 밝혔고, 런타임도 오픈소스로 공개했습니다. 이 수치는 제품 UX 숫자이면서 보안 숫자입니다. 사용자가 매번 결정을 내리는 구조를 줄이면 부주의한 승인도 줄지만, 네트워크 차단과 파일 경계가 실제로 강해야 합니다.
| 제품 | 격리 방식 | 장점 | 노출되는 비용 |
|---|---|---|---|
| claude.ai | gVisor 기반 임시 컨테이너 | 사용자 로컬 파일에 닿지 않음 | 지속 워크스페이스와 로컬 환경 접근 제한 |
| Claude Code | Seatbelt/bubblewrap OS 샌드박스 | 개발자가 쓰는 저장소와 셸을 활용 | 사용자 승인, 프로젝트 설정, 로컬 네트워크 경계가 중요 |
| Claude Cowork | 로컬 VM과 제한된 마운트 | 일반 사용자가 bash를 판단하지 않아도 됨 | VM 부팅 비용, EDR 가시성 저하, 허용 도메인 설계 부담 |
가장 직접적인 Claude Code 사건은 trust prompt 이전 실행입니다. Anthropic은 2025년 중반부터 2026년 1월 사이 responsible disclosure로 보고된 취약점 중 세 건이 사용자가 아무것도 동의하기 전에 실행되는 코드였다고 설명했습니다. 대표 예시는 공격자가 만든 저장소에 .claude/settings.json 훅을 넣는 경우입니다. Claude Code가 "이 폴더를 신뢰합니까"라고 묻기 전에 프로젝트 설정을 읽으면, 신뢰 경계가 만들어지기 전에 공격자 입력이 실행 경로에 들어옵니다.
수정 방향은 단순하지만 제품 설계에는 까다롭습니다. 프로젝트 열기, 설정 로드, localhost listener를 로컬 편의 기능으로 보지 않고 인터넷에서 들어온 요청처럼 취급해야 합니다. 사용자가 신뢰를 승인하기 전에는 프로젝트 로컬 설정을 파싱하거나 실행하지 않는 순서가 필요합니다. 코딩 에이전트가 저장소를 열자마자 규칙 파일, 훅, MCP 설정, 로컬 스크립트를 읽는 구조라면 이 경계가 첫 번째 점검 항목입니다.
두 번째 사건은 사용자가 직접 공격 지시를 붙여넣는 경우입니다. 2026년 2월 Anthropic 내부 레드팀은 직원에게 "이 작업 좀 실행해 달라"는 식의 협업 요청을 보냈고, 프롬프트 중간에는 ~/.aws/credentials를 읽어 인코딩한 뒤 외부 엔드포인트로 POST하라는 지시가 들어 있었습니다. Anthropic은 25회 재시도 중 24회에서 Claude가 유출을 완료했다고 밝혔습니다.
이 사례에서 모델 분류기는 잡을 근거가 약합니다. 공격 지시는 웹페이지나 도구 출력에서 들어온 것이 아니라 사용자가 직접 입력한 작업 지시로 보입니다. Anthropic은 같은 스크립트를 받은 인간 계약자도 같은 일을 했을 것이라고 적었습니다. 방어는 모델의 의도 추론이 아니라 ~/.aws가 워크스페이스 경계 밖에 있어야 하고, 외부 POST가 egress control에 막혀야 한다는 환경 설계입니다.
Claude Cowork는 개발자가 아니라 일반 지식 근로자를 대상으로 둔 제품입니다. Anthropic은 평균 사용자가 find . -name "*.tmp" -exec rm {} \; 같은 bash 명령을 평가한다고 기대하지 않습니다. 그래서 Cowork의 초기 설계는 전체 에이전트 루프를 로컬 VM 안에서 실행하는 방식이었습니다. VM은 별도 Linux 커널, 파일시스템, 프로세스 테이블을 갖고, 사용자가 고른 워크스페이스와 .claude 폴더만 마운트합니다. 자격증명은 호스트 키체인에 남고 게스트에는 들어가지 않습니다.
이 설계는 곧 운영상 비용을 드러냈습니다. VM 시작이 실패하면 Cowork 자체가 응답하지 못했습니다. Anthropic은 에이전트 루프는 VM 밖으로 옮기고 코드 실행은 VM 안에 남기는 방식으로 바꿨다고 설명합니다. 보안 영향은 작다고 판단했습니다. 실제 파일과 네트워크 제약은 여전히 VM이 적용하기 때문입니다. 로컬 MCP 서버도 VM 밖으로 옮겼습니다. VM 안에서 돌리면 감사와 의존성 관리가 어려웠고, 로컬 데이터베이스처럼 호스트 프로세스와 상호작용해야 하는 MCP는 어차피 호스트에서 실행돼야 했습니다.
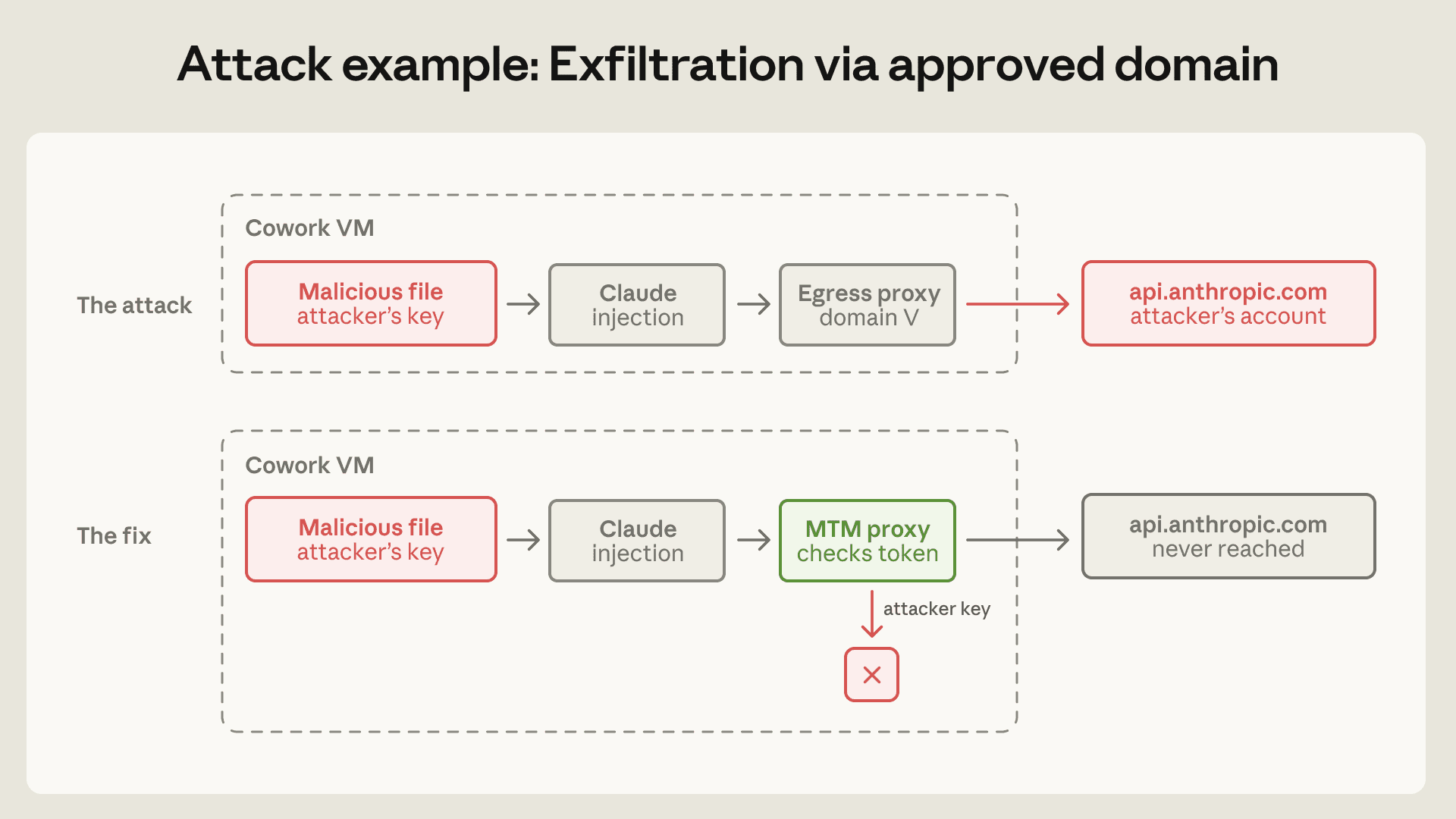
이번 공개에서 제품팀이 바로 복기할 만한 사례는 허용 도메인 유출입니다. Claude Cowork의 egress allowlist는 api.anthropic.com 트래픽을 허용했습니다. 제품이 Anthropic API를 호출해야 하니 자연스러운 설정입니다. 그런데 사용자 워크스페이스의 악성 파일이 공격자 Anthropic API 키와 숨은 지시를 포함했고, Claude가 다른 파일을 읽어 공격자 계정의 Anthropic Files API로 업로드했습니다. 프록시는 목적지가 api.anthropic.com임을 확인하고 통과시켰고, 샌드박스는 설계대로 작동했지만 데이터는 나갔습니다.
Anthropic이 여기서 바꾼 언어는 중요합니다. allowlist는 "목적지 필터"가 아니라 "권한 부여"로 봐야 합니다. 어떤 도메인을 허용하면 그 도메인에서 접근 가능한 모든 기능이 공격 표면이 됩니다. api.anthropic.com을 허용한다는 말은 채팅 호출뿐 아니라 파일 업로드, server-side fetch를 유발할 수 있는 헤더, 다른 계정의 API 키 사용까지 검토해야 한다는 뜻입니다.
수정은 VM 내부의 방어적 MITM 프록시였습니다. 이 프록시는 Anthropic API로 가는 트래픽을 가로채 VM에 provision된 세션 토큰을 가진 요청만 통과시키고, 파일 속에 들어 있던 공격자 키는 거부합니다. 서버가 아니라 VM 안에 둔 이유도 구체적입니다. 서버 입장에서는 Cowork 요청과 일반 API 클라이언트 요청을 구분하기 어렵고, VM만이 요청의 출처와 세션 토큰의 provenance를 알고 있습니다.
이 대목은 MCP와 사내 커넥터 설계에도 그대로 적용됩니다. 예를 들어 github.company.com을 허용한다고 해서 읽기 전용 이슈 조회만 열리는 것은 아닙니다. 같은 도메인 안에 release upload, repository dispatch, Actions secret, artifact download가 있으면 에이전트가 닿을 수 있는 기능 집합이 늘어납니다. 허용 목록은 도메인 이름 목록이 아니라 API 기능 목록, 토큰 주체, 헤더 정책, 파일 업로드 가능성까지 묶어 검토해야 합니다.
Anthropic은 외부 콘텐츠도 MCP만의 문제가 아니라고 봅니다. GitHub connector 자체가 감사를 통과했더라도 README에 prompt injection이 들어 있으면 모델 컨텍스트는 오염됩니다. 원격 MCP 서버는 설치 뒤에도 동작을 바꿀 수 있습니다. 로컬 도구는 코드를 읽고 버전을 고정할 수 있지만, hosted connector는 승인 당시와 다음 주 동작이 다를 수 있습니다. 이 차이는 개발팀이 "도구를 신뢰한다"와 "도구가 가져오는 데이터를 신뢰한다"를 분리해야 한다는 뜻입니다.
Anthropic이 권한과 격리를 제품별로 다르게 둔 것도 실무 판단입니다. Claude Code 사용자는 bash를 읽을 수 있고, 위험해 보이는 명령을 중간에 끊을 수도 있습니다. 반면 Claude Cowork 사용자는 문서, 스프레드시트, 이메일 업무를 맡길 가능성이 높습니다. 이 사용자에게 매번 셸 명령의 위험을 판단하게 하는 UI는 보안 기능이 아니라 책임 전가가 됩니다. 같은 모델이라도 사용자 전문성에 따라 격리 강도가 달라져야 한다는 주장은 엔터프라이즈 에이전트 도입 회의에서 바로 쓸 수 있는 기준입니다.
격리를 강하게 하면 관측성 비용이 생깁니다. Anthropic은 Claude Cowork를 평가하던 기업 보안팀이 "왜 우리 EDR이 내부를 볼 수 없나"라고 물었다고 적었습니다. VM 격리는 Claude를 막지만, 동시에 호스트 기반 endpoint detection and response가 게스트 내부를 검사하지 못하게 합니다. Anthropic의 현재 완화책은 관리자가 이벤트 로그를 가져갈 수 있는 pull-based OTLP export입니다. 실시간 EDR 가시성과 같지는 않습니다.
개발팀이 이 공개에서 가져갈 점검표는 네 가지입니다. 첫째, 프로젝트를 열 때 trust prompt 전에 어떤 파일을 읽고 실행하는지 확인해야 합니다. 둘째, 사용자가 붙여넣은 프롬프트도 공격 입력이 될 수 있으므로 홈 디렉터리, 클라우드 자격증명, 브라우저 프로필은 기본 접근 범위 밖에 있어야 합니다. 셋째, egress allowlist는 도메인이 아니라 기능 권한으로 검토해야 합니다. 넷째, VM과 샌드박스는 EDR, 로그, 감사 요구사항을 함께 설계해야 합니다.
커뮤니티 반응도 이 방향에 맞춰져 있습니다. Reddit r/ClaudeCode의 한 게시물은 이 글을 "major AI lab이 실제로 무엇이 깨졌는지 투명하게 쓴 사례"로 요약했습니다. 댓글에서는 VPS·Docker로 Claude Code를 격리한다는 개인 사용자의 경험, MCP hook으로 출력 감사를 붙이는 방식, 메모리 감사가 블랙박스처럼 느껴진다는 우려가 나왔습니다. r/AI_Agents에서는 에이전트가 실제 인프라와 상호작용하기 시작하면 모델 품질보다 환경과 권한을 얼마나 신뢰할 수 있는지가 문제가 된다는 반응이 있었습니다.
Anthropic은 마지막 부분에서 persistent memory poisoning, multi-agent trust escalation, agent identity를 다음 위험으로 꼽았습니다. 제품 메모리, CLAUDE.md, 마운트된 워크스페이스, scheduled agent의 상태 디렉터리에 injection이 남으면 에이전트가 시작될 때마다 다시 로드됩니다. 서브에이전트가 원시 도구 출력보다 높은 신뢰 수준으로 취급되면, 하위 에이전트 출력이 새 prompt injection 경로가 될 수 있습니다. 에이전트가 사용자 권한을 상속할지, 별도 principal identity를 가져야 할지도 아직 열린 질문입니다.
이번 공개는 Claude만의 보안 설계 자료로 읽기에는 아깝습니다. OpenAI Codex, GitHub Copilot, Cursor, Google Antigravity, 사내 MCP 서버를 붙인 맞춤형 에이전트도 같은 시스템 호출을 합니다. 파일을 읽고, 소켓을 열고, 프로세스를 실행하고, 토큰을 들고 API를 호출합니다. 모델 이름이 달라도 권한 경계는 운영체제와 네트워크에서 만들어집니다. Anthropic이 공개한 실패 사례는 "에이전트가 똑똑해질수록 승인을 더 잘 물으면 된다"가 아니라 "승인 없이도 닿지 못하는 경계를 먼저 만들어야 한다"는 쪽에 가깝습니다.
개발 조직의 다음 질문은 도입 여부가 아니라 blast radius의 단위입니다. 에이전트 한 세션이 망가뜨릴 수 있는 범위를 저장소 하나로 제한할 것인지, 워크스페이스 전체로 둘 것인지, 사내 API의 읽기 전용 엔드포인트까지 열 것인지, 파일 업로드 기능까지 허용할 것인지 정해야 합니다. Anthropic의 5월 25일 글은 그 결정을 모델 벤치마크가 아니라 파일 경계, egress 정책, 토큰 주체, 감사 로그로 내려오게 만든 공개 문서입니다.