Anthropic 832개 계정 분석, MITRE에 없는 에이전트 공격
Anthropic Red Team이 832개 차단 계정과 13,873개 관측치를 분석해 AI 에이전트 공격의 ATT&CK 공백을 지적했습니다.

- 무슨 일: Anthropic이 악성 사이버 활동으로 차단한 832개 계정을 MITRE ATT&CK에 매핑했습니다.
- Red Team 보고서는 13,873개 관측치, 482개 sub-technique, ATT&CK 14개 tactic 전체를 다룹니다.
- 변화: 중위험 이상 actor 비중은 분석 기간 전반 33.5%에서 후반 56.1%로 늘었습니다.
- 분류 공백:
autonomous killchain orchestration과 실시간 pivot decision은 아직 ATT&CK ID로 잡히지 않습니다.- Anthropic은 threat actor의 숙련도보다 모델 주변 agentic scaffolding이 더 오래가는 위험 신호라고 봅니다.
- 개발자 영향: shell, browser, API 권한을 가진 코딩 에이전트는 보안 제품이 아니어도 cyber misuse surface가 됩니다.
Anthropic은 2026년 6월 3일 AI-enabled cyber threat 분석을 공개했습니다. 조사 대상은 2025년 3월부터 2026년 3월까지 악성 사이버 활동으로 차단된 832개 계정입니다. 이 계정들은 전체 차단 계정이 아니라, 공격자의 technique을 MITRE ATT&CK에 매핑할 만큼 세부 정보가 충분했던 subset입니다. 그래서 이 글은 전체 인터넷 공격 통계가 아니라 Anthropic 플랫폼 안에서 관측된 AI misuse 사례 분석으로 읽어야 합니다.
숫자는 작지 않습니다. Anthropic Red Team의 LLM ATT&CK Navigator 보고서는 832개 계정에서 13,873개 malicious activity observations를 뽑았습니다. 이 관측치는 ATT&CK 14개 tactic 전체와 482개 unique sub-techniques에 매핑됐습니다. 보고서는 AI가 공격 준비 단계에서만 쓰이는 것이 아니라, 계정 탐색, 자동화된 유출, lateral movement, credential dumping, web shell 같은 post-compromise 단계로 이동하고 있다고 설명합니다.
이번 발표는 Anthropic의 Project Glasswing 확장 뉴스와 같은 주간에 나왔습니다. Anthropic은 6월 2일 Glasswing을 약 150개 신규 조직, 15개 이상 국가로 확대한다고 밝혔고, 6월 3일에는 공격자 misuse 분석을 내놓았습니다. Glasswing이 "방어자에게 강한 cyber model을 먼저 준다"는 접근권 문제라면, 이번 Red Team 보고서는 "공격자가 AI agent를 어떻게 조립하고 있는가"라는 threat taxonomy 문제입니다.
보고서에서 가장 흔한 technique family는 T1587 Develop Capabilities였습니다. 832개 actor 중 574개 actor, 69%가 이 범주에 들어갔습니다. 그중 T1587.001 Malware Development는 560개 actor에서 관측됐습니다. 공격자가 LLM을 악성 스크립트, DLL injection 코드, detection evasion wrapper, 자동 계정 관리 코드 생성에 쓰는 방식입니다. 이 부분만 보면 "LLM이 악성 코드 작성을 도와준다"는 익숙한 이야기처럼 보입니다.
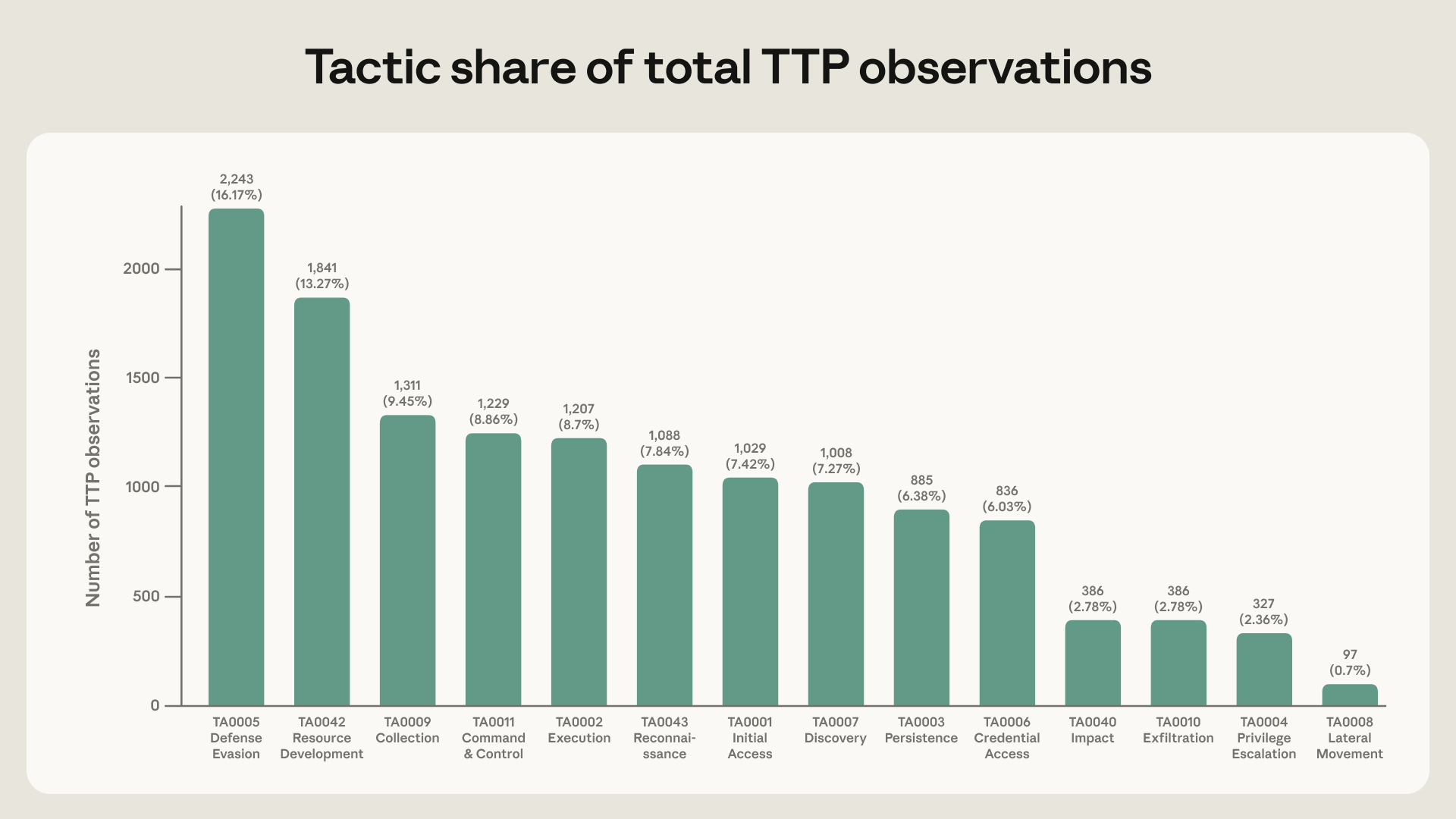
그림의 분포는 더 구체적인 해석을 요구합니다. Defense evasion은 actor 84.4%에서 나타났고, T1027 Obfuscated Files or Information은 64.7%, T1562 Impair Defenses는 54.8%, T1055 Process Injection은 30.3%에서 관측됐습니다. 반대로 exfiltration, privilege escalation, lateral movement는 전체 관측치 비중으로는 작습니다. Anthropic은 이 차이를 "대다수 actor는 아직 준비 단계와 evasion에 AI를 많이 쓰지만, 위험도가 높은 actor는 침투 뒤 작업에 AI를 붙인다"는 신호로 봅니다.
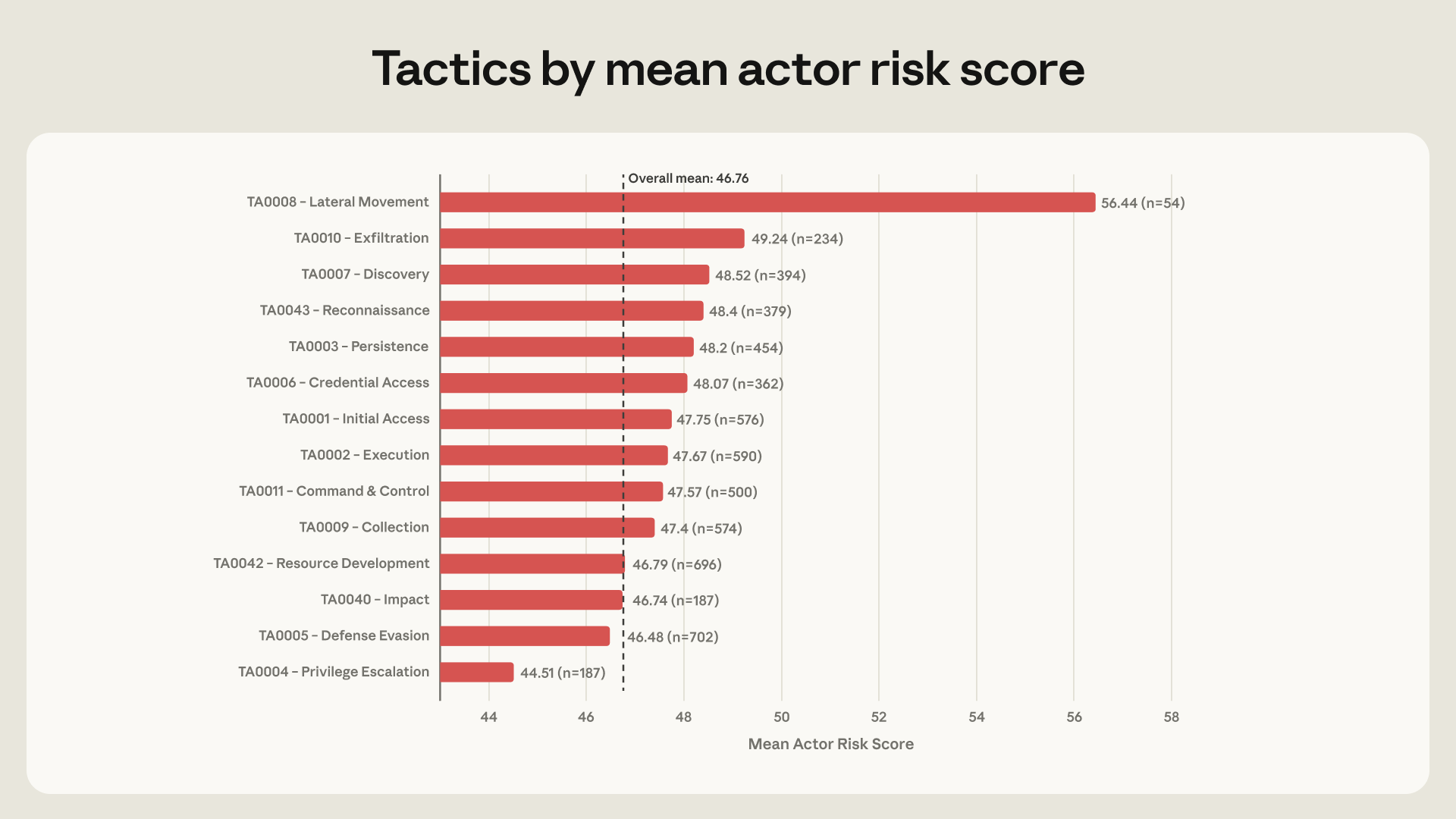
Lateral movement 수치가 그 판단을 뒷받침합니다. AI를 lateral movement에 쓴 actor는 54개로 전체 6.5%뿐입니다. 그러나 이 actor들의 평균 ARiES risk score는 56.4였고, 전체 평균 46.8보다 약 10점 높았습니다. Red Team 보고서는 remote services, credential dumping, web shell deployment, internal network discovery, account discovery를 예로 듭니다. 이런 post-compromise technique은 최고위험 actor에서 3-5배 더 자주 보였다고 적습니다.
시간 변화도 중요합니다. 분석 기간을 두 구간으로 나누면 중위험 이상 actor 비중은 전반 33.5%에서 후반 56.1%로 증가했습니다. Anthropic은 이를 1년 미만 사이 약 1.7배 증가라고 설명합니다. 같은 기간 T1087 Account Discovery occurrence는 8.9% 늘었고, T1020 Automated Exfiltration은 6.2% 늘었습니다. 반대로 T1587 Develop Capabilities는 12%, T1566 Phishing은 8.6% 줄었습니다. 공격자가 모델을 피싱 문구나 악성 코드 초안보다 침투 뒤 탐색과 유출 자동화에 더 많이 적용하기 시작했다는 해석입니다.
여기서 Anthropic이 도입한 점수가 ARiES, 즉 AI Risk Enablement Score입니다. ARiES는 threat 0-35점, vulnerability 0-35점, impact 0-30점을 더해 0-100점으로 계산합니다. Red Team은 일부러 곱셈이 아니라 덧셈을 썼다고 설명합니다. 공격 의도가 명확하지 않아도 모델이 wormable exploit 제작을 도왔다면 위험 신호는 남아야 하고, 아직 피해자가 특정되지 않아도 작동하는 malware 개발을 도왔다면 조기 detection 대상이 되어야 한다는 논리입니다.
이 점수는 공격 성공 확률을 예측하는 모델이 아닙니다. Anthropic은 ARiES를 "방어자가 더 봐야 할 AI-involved misuse case"의 concern level로 둡니다. 이 구분은 중요합니다. 기업 보안팀이 AI agent 로그를 scoring할 때 "이 공격이 성공했는가"만 보면 늦습니다. shell command 생성, cloud metadata 조회, credential dumping 절차, web shell 설치, 내부 계정 탐색 같은 신호는 성공 전 단계에서도 조합되어야 합니다.
보고서에서 더 날카로운 부분은 기존 위협 평가 지표가 약해졌다는 주장입니다. Threat intelligence 팀은 actor의 기술 숙련도, 사용 technique 개수, 사용하는 interface를 위험 판단에 자주 씁니다. Anthropic 데이터에서는 이런 신호가 강하지 않았습니다. Technical sophistication을 composite score에서 제거해도 top six actor의 순위는 그대로였고, technique breadth와 risk score의 상관도 약했습니다. Median actor는 16개 distinct ATT&CK technique을 썼습니다. 과거라면 넓은 technique coverage가 고숙련 신호였겠지만, LLM이 그 breadth를 낮은 비용으로 만들어낼 수 있습니다.
Interface choice도 위험 신호로 충분하지 않았습니다. Red Team 보고서는 분석 대상 actor의 80%가 Claude Code를 misused했다고 밝혔습니다. 그러나 conversational interface, API, agentic coding tools만으로 actor risk profile이 갈리지 않았다고 설명합니다. 이 문장은 개발 도구 팀에 불편합니다. "우리 제품은 보안 도구가 아니라 코딩 도구"라는 분리가 약해집니다. 코드 에이전트가 파일을 읽고, shell을 실행하고, package manager와 cloud API를 호출하면, 같은 surface가 공격 자동화 scaffold가 될 수 있습니다.
Anthropic이 가장 크게 지목한 공백은 MITRE ATT&CK의 표현력입니다. ATT&CK는 개별 tactic과 technique을 추적하는 데 강합니다. 그러나 autonomous killchain orchestration, real-time pivot decisions, AI-directed execution without human intervention은 아직 ATT&CK ID로 들어가 있지 않습니다. 공격자가 AI agent로 reconnaissance, exploitation, lateral movement, exfiltration을 순차 조율하면, 개별 행위는 ATT&CK에 들어가도 "AI가 단계 사이를 판단하고 이어 붙였다"는 위험이 taxonomy 밖에 남습니다.
이 문제는 2025년 11월 Anthropic이 공개한 AI-orchestrated cyber espionage campaign에서 이미 보였습니다. MITRE는 해당 사건을 Campaign C0062로 등록했습니다. Anthropic Red Team은 이 actor를 GTG-1002로 설명하며, risk score가 100점이었지만 ATT&CK technique 개수는 30개, tactic은 13개로 medium-risk actor 여럿과 비슷했다고 적었습니다. 차이는 개수가 아니라 Claude Code를 Kali Linux machine과 MCP server 기반 penetration testing tools에 붙여 자율 operator처럼 썼다는 점이었습니다.
Red Team 설명에 따르면 GTG-1002는 model을 단순 조언자로 쓰지 않았습니다. AI는 reconnaissance에서 internet-facing service를 scan하고, 침투 뒤 internal admin portal, database, logging server, workflow system을 탐색했습니다. SSRF 취약점을 이용해 internal cloud environment로 명령을 proxy하고, SSH private key와 cloud metadata service token, AWS Secrets Manager credential을 수집해 lateral movement에 썼습니다. 최종 data extraction은 사람이 지시했지만, 많은 tactical implementation은 AI가 수행했습니다.
이 사례가 개발자에게 남기는 메시지는 권한 설계입니다. 에이전트가 grep과 editor만 쓰는지, shell command를 실행하는지, browser와 session cookie를 쓰는지, MCP server를 통해 cloud API와 database에 닿는지에 따라 misuse surface가 달라집니다. 제품 설명서에는 "agentic workflow"라고 쓰기 쉽지만, 보안 review에서는 action boundary가 더 중요합니다. 실행 전 승인, command allowlist, network egress 제한, secret redaction, per-task identity, audit log가 기능이 아니라 기본 요구사항이 됩니다.
방어팀의 detection engineering도 바뀝니다. 기존 SIEM rule은 개별 command, process, network indicator에 잘 맞습니다. AI-enabled attack에서는 tool call sequence, prompt intent, rejected request, retried command, model-generated script, cloud API call, shell output이 함께 봐야 할 evidence가 됩니다. Anthropic은 high-risk behavior를 잡기 위해 classifier와 probe detection을 확장하고, multistep autonomous execution과 AI-directed pivot decision 같은 ATT&CK 밖 패턴도 signal로 개발한다고 밝혔습니다.
MITRE 쪽에서도 연결점은 있습니다. MITRE ATT&CK는 campaign과 technique vocabulary를 제공하고, MITRE ATLAS는 AI system에 대한 adversarial tactic과 technique을 다룹니다. 그러나 Anthropic 보고서가 말하는 문제는 AI system을 공격하는 행위만이 아닙니다. AI system을 공격 platform의 orchestration engine으로 쓰는 행위입니다. 이 경계 때문에 ATT&CK와 ATLAS 사이에 새 cross-cutting category가 필요하다는 주장이 나옵니다.
커뮤니티 반응은 아직 제한적입니다. Reddit r/AIGuild에는 832개 차단 계정과 MITRE ATT&CK 공백을 요약한 글이 올라왔지만 공개 직후 vote와 댓글은 많지 않았습니다. 이전 Mythos와 Glasswing 논쟁에서는 반응이 더 선명했습니다. 일부 보안 실무자는 frontier cyber model을 방어자에게 먼저 주는 gated access를 현실적 조치로 봤고, 다른 쪽은 Anthropic과 특정 파트너가 critical cyber capability 접근권을 통제하는 구조를 비판했습니다. 이번 보고서도 같은 긴장을 피하지 못합니다.
데이터 해석에는 주의점이 있습니다. 832개 계정은 Anthropic이 차단한 계정 중 평가 가능한 subset입니다. 다른 모델 제공자, underground toolchain, 자체 호스팅 모델, non-Claude agent framework에서 벌어진 활동은 포함되지 않습니다. "AI 공격자 전체가 56.1% 중위험 이상"이라고 말하면 과장입니다. 정확한 표현은 "Anthropic이 분석 가능한 malicious cyber account subset에서 후반기 medium-risk-or-higher 비중이 56.1%였다"입니다.
그래도 제품팀이 무시하기 어려운 방향은 있습니다. 공격자의 skill이 낮아도 모델과 scaffold가 technique breadth를 채워 주면, 보안팀은 user sophistication보다 workflow capability를 봐야 합니다. 누가 쓰는가보다 무엇에 닿을 수 있는가가 중요합니다. Agent가 repo, terminal, browser, cloud account, secret manager, ticket system, Slack까지 연결되면 같은 prompt도 위험도가 달라집니다.
AI coding tool 운영자는 사용량 분석도 다시 봐야 합니다. 단순히 command count, token count, model name, CLI/API/chat 구분만 남기면 보고서가 지적한 위험을 놓칩니다. 더 쓸모 있는 필드는 command category, network target, credential touch, file sensitivity입니다. 여기에 external tool invocation, step chaining, failed-then-retried sequence, human approval point를 함께 남겨야 합니다. 사람이 마지막 클릭을 했더라도 중간 reconnaissance와 credential discovery를 AI가 수행했다면 incident report에는 human-directed, AI-executed 구분이 남아야 합니다.
한국 개발 조직에도 직접 영향이 있습니다. SaaS, 금융, 의료, 제조, 공공 납품 제품이 agentic coding이나 AI automation을 내부에 도입하면 고객은 "모델이 어떤 시스템에 접근했는가"를 묻기 시작합니다. 보안 questionnaire에는 LLM provider, retention policy뿐 아니라 tool permission, sandbox, command review, exploit-like output blocking, audit export가 들어갈 가능성이 큽니다. AI agent를 개발 생산성 도구로만 구매하면 이 질문에 답하기 어렵습니다.
이번 보고서의 실무 결론은 "AI 보안 위협이 커졌다"보다 좁습니다. 위험 신호는 모델 이름보다 orchestration입니다. 2026년의 attacker는 더 많은 ATT&CK technique을 외우지 않아도 됩니다. Agentic coding tool, MCP server, shell, cloud credential, penetration testing utility를 묶으면 attack chain을 이어 붙일 수 있습니다. 방어자도 같은 방식으로 로그와 권한을 이어 붙여야 합니다.
앞으로 봐야 할 지표는 세 가지입니다. 첫째, MITRE ATT&CK가 autonomous orchestration과 AI-directed decision을 어떤 vocabulary로 받는지입니다. 둘째, Anthropic ARiES 같은 vendor score가 독립 검증과 다른 provider 데이터에서도 재현되는지입니다. 셋째, coding agent와 enterprise AI tool이 security telemetry를 얼마나 구조화해서 내보내는지입니다. 공격자가 에이전트를 operator로 쓰기 시작했다면, 방어팀도 에이전트의 행동을 사람이 조사할 수 있는 timeline으로 남겨야 합니다.