AI Agent Index, 안전 공개 없는 에이전트 25개의 경고
2025 AI Agent Index는 30개 에이전트 중 25개가 내부 안전 결과를 공개하지 않았고, 자율성은 더 빨리 높아졌다고 지적합니다.

- 무슨 일:
2025 AI Agent Index가 30개 주요 배포형 AI 에이전트의 기능, 자율성, 안전 공개 수준을 비교했습니다.- 2026년 5월 6일 arXiv v2가 공개됐고, 공식 사이트는 45개 필드 기준의 에이전트별 주석을 제공합니다.
- 핵심 숫자: 25/30은 내부 안전 결과를 공개하지 않았고, 23/30은 제3자 테스트 정보가 없었습니다.
- 의미: 에이전트 도입의 병목은 모델 성능보다
권한,로그,평가 증거를 요구하는 조달 기준으로 이동합니다. - 주의점: Index는 공개 정보 기반 스냅샷입니다. 문서가 없다는 말은 안전 조치가 없다는 뜻이 아니라, 외부 검증이 어렵다는 뜻입니다.
AI 에이전트 시장을 볼 때 가장 쉬운 관찰은 "무엇을 할 수 있는가"입니다. 브라우저를 조작하고, 코드를 고치고, CRM 레코드를 업데이트하고, 티켓을 분류하고, 결제를 준비하고, 보고서를 생성합니다. 최근 몇 달 동안 나온 제품 발표도 대부분 이 방향이었습니다. 더 긴 작업, 더 많은 도구, 더 많은 커넥터, 더 높은 자율성입니다.
그런데 기업이 실제로 에이전트를 도입할 때 더 어려운 질문은 따로 있습니다. 이 에이전트는 어떤 권한으로 행동합니까. 중간에 멈출 수 있습니까. 어떤 도구를 호출했는지 볼 수 있습니까. 내부 안전 테스트 결과는 있습니까. 제3자 평가를 받았습니까. 외부 웹사이트에 접근할 때 자신이 에이전트라고 식별합니까. 사고가 났을 때 모델 제공자, 에이전트 제작사, 배포 조직 중 누가 어떤 책임을 집니까.
2026년 5월 6일 개정 공개된 The 2025 AI Agent Index는 이 질문을 정면으로 다룹니다. MIT CSAIL, University of Cambridge, Harvard Law School, Stanford University, Concordia AI, University of Pennsylvania, Hebrew University 연구진이 참여한 이 프로젝트는 30개 주요 배포형 AI 에이전트를 45개 필드로 문서화했습니다. 공식 AI Agent Index 사이트는 이를 대화형 데이터베이스와 주요 지표로 공개하고 있습니다.
이 글의 핵심은 "어떤 에이전트가 최고인가"가 아닙니다. 오히려 반대입니다. 이제 시장은 에이전트 기능을 빠르게 늘리고 있지만, 외부에서 확인 가능한 안전 평가와 책임 문서는 그 속도를 따라가지 못하고 있습니다. Index가 보여주는 가장 중요한 숫자는 30개 중 24개가 2024-2025년에 출시되거나 주요 agentic update를 받았다는 사실이 아니라, 25개가 내부 안전 결과를 공개하지 않았고 23개가 제3자 테스트 정보를 공개하지 않았다는 사실입니다.
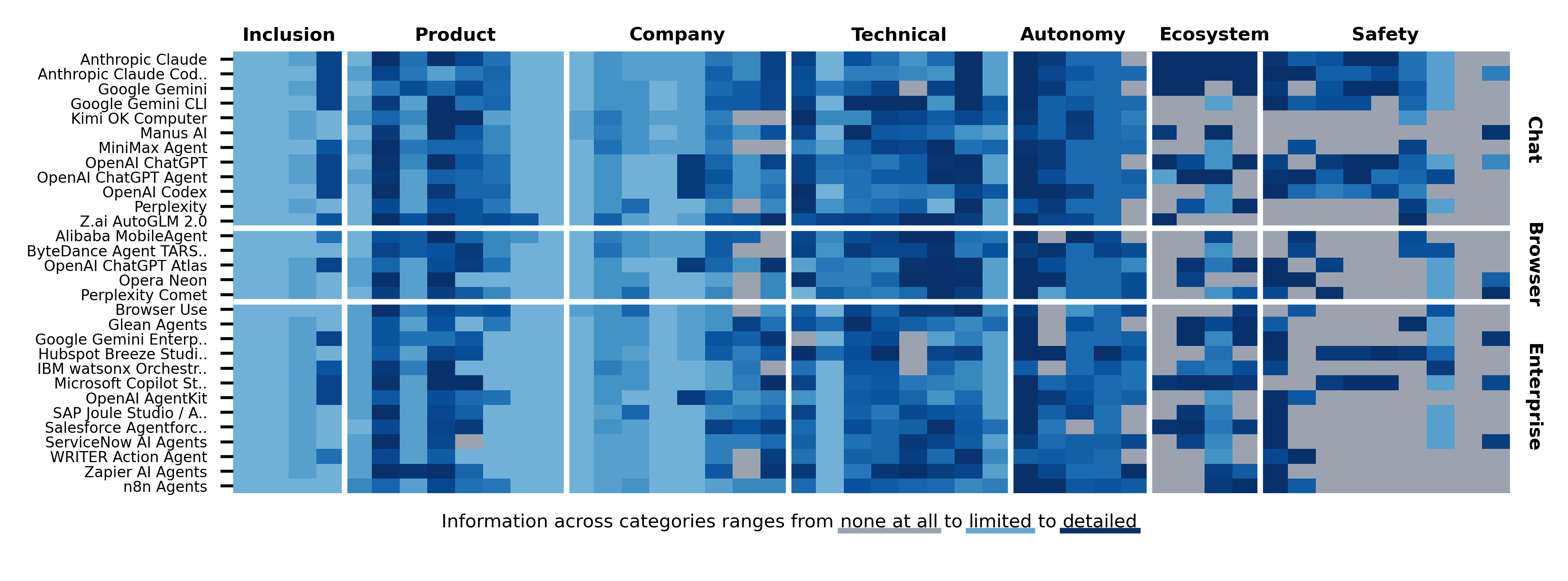
30개 에이전트를 45개 필드로 본 이유
AI Agent Index는 에이전트를 단순히 모델 이름이나 제품명으로 나누지 않습니다. 연구진은 후보 95개를 검토한 뒤, agency, impact, practicality 기준을 만족하는 30개를 골랐습니다. 기준일은 2025년 12월 31일입니다.
여기서 agency는 최소한의 인간 감독, 장기 목표와 하위 목표, 도구와 API를 통한 환경 상호작용, 여러 작업에 적응하는 범용성을 봅니다. impact는 검색량, GitHub stars, 기업 가치, frontier model forum이나 safety commitment 참여 같은 시장성과 공적 관심을 봅니다. practicality는 공개 접근성, 즉시 배포 가능성, 특정 산업에만 묶이지 않는 일반성을 뜻합니다.
선정된 30개는 세 범주로 나뉩니다. Chat agent 12개, browser agent 5개, enterprise agent 13개입니다. 목록에는 Claude, Claude Code, Gemini, Gemini CLI, ChatGPT, ChatGPT Agent, Codex, Perplexity, Comet, Manus, Copilot Agents, Agentforce, Joule Agents, ServiceNow AI Agents, Zapier Agents 같은 제품이 들어갑니다. 이미 개발자와 기업이 실제로 쓰거나 검토하는 이름들입니다.
주석 필드는 여섯 범주입니다. 제품 개요, 회사와 책임성, 기술 능력과 아키텍처, 자율성과 통제, 생태계 상호작용, 안전과 평가와 영향입니다. 7명의 subject-matter expert가 에이전트별이 아니라 필드별로 주석을 달았고, 모든 주석은 최소 한 명의 다른 annotator가 검토했습니다. 1,350개 필드 중 37개에서 생긴 불일치는 토론으로 해소했다고 설명합니다.
이 방법론이 중요한 이유는 에이전트 시장의 비교 기준을 바꾸기 때문입니다. 보통 우리는 "이 도구가 브라우저를 쓸 수 있나", "코드를 고칠 수 있나", "MCP를 지원하나"를 묻습니다. Index는 여기에 "그 기능이 어떤 평가 증거와 함께 공개됐나"를 붙입니다. 이는 제품 리뷰가 아니라 조달 문서에 더 가까운 관점입니다.
숫자는 기능 확산보다 공개 공백을 말합니다
공식 사이트의 key findings는 시장의 양면을 동시에 보여줍니다. 한쪽에서는 에이전트 배포가 빠르게 늘고 있습니다. 30개 중 24개가 2024-2025년에 출시되거나 주요 에이전트 기능 업데이트를 받았습니다. 구글 스칼라에서 "AI agent" 또는 "agentic AI"를 언급한 논문 수도 이전 연도 전체를 넘어섰다고 설명합니다.
다른 한쪽에서는 공개 정보가 비어 있습니다. AI Agent Index는 1,350개 필드 중 227개에서 공개 정보를 찾지 못했다고 밝힙니다. 특히 Ecosystem Interaction과 Safety 범주에 빈칸이 집중됩니다. 에이전트가 실제 세계의 웹, API, 사내 시스템과 상호작용할수록 중요한 부분이 바로 여기인데, 공개 문서는 오히려 그곳에서 약합니다.
가장 눈에 띄는 수치는 4/13입니다. Index는 frontier 수준의 자율성을 보이는 13개 에이전트 중 agentic safety evaluation을 공개한 것이 4개뿐이라고 정리합니다. 사이트의 further details는 이 4개를 ChatGPT Agent, OpenAI Codex, Claude Code, Gemini 2.5 Computer Use로 설명합니다. 즉 더 자율적인 에이전트가 많아지고 있지만, 그 자율성을 에이전트 구성 전체에서 시험한 공개 자료는 일부 대형 연구소 제품에 치우쳐 있습니다.
여기서 중요한 표현은 "agentic safety evaluation"입니다. 모델 안전 평가는 이제 익숙합니다. 유해 발화, 생물학, 사이버, 자율성, 설득, 환각 같은 모델 차원의 평가가 공개됩니다. 그러나 에이전트는 모델 하나가 아닙니다. 프롬프트, planner, tool router, browser, memory, file access, connector, policy, approval state, deployment environment가 함께 작동합니다. 모델이 안전하다고 해서 에이전트 하네스가 안전하다고 결론낼 수 없습니다.
자율성은 제품 유형마다 다르게 올라갑니다
Index의 자율성 분류도 실무적으로 중요합니다. Chat agent는 대체로 L1-L3 수준에 머뭅니다. 사용자가 턴 단위로 지시하고, 에이전트는 답변이나 제한된 도구 호출을 수행합니다. 물론 Claude Code나 Codex처럼 긴 작업을 처리하는 제품은 chat이라는 표면을 갖고 있어도 실행은 훨씬 복잡합니다. 그래도 사용자가 대화 루프 안에서 계속 방향을 잡는 경우가 많습니다.
Browser agent는 다릅니다. Index는 browser agent가 L4-L5에서 동작하며, 실행 중 인간 개입이 제한적이라고 설명합니다. 브라우저 에이전트는 웹페이지를 탐색하고, 폼을 채우고, 버튼을 누르고, 외부 시스템의 상태를 바꿀 수 있습니다. 여기서는 단순 답변 오류가 아니라 실제 웹 행위의 문제가 됩니다. 어떤 사이트에 어떤 user-agent로 접근했는지, robots.txt를 존중했는지, anti-bot 보호를 우회했는지, 결제나 예약 같은 행동 전에 확인을 요구했는지가 중요해집니다.
Enterprise agent는 다시 다른 패턴입니다. 설계 단계에서는 L1-L2입니다. 관리자가 자연어로 에이전트를 만들고, 도구를 붙이고, 데이터 접근 범위를 정합니다. 하지만 배포된 뒤에는 이벤트 트리거에 따라 L3-L5로 움직일 수 있습니다. 예를 들어 티켓이 생성되면 에이전트가 분류하고, 고객 데이터와 정책 문서를 조회하고, 워크플로를 진행하고, 승인 요청을 만들 수 있습니다. 사용자는 설계 시점에 통제했지만, 실행 시점에는 에이전트가 업무 시스템 안에서 움직입니다.
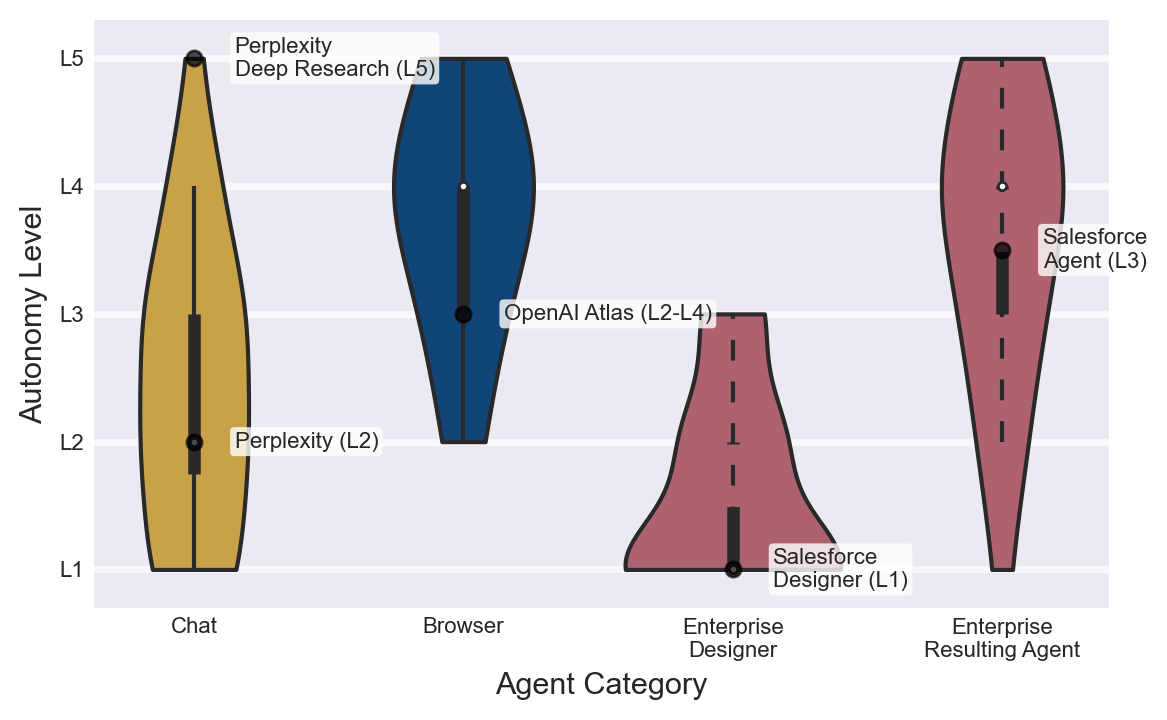
이 구분은 개발자에게 직접적인 의미가 있습니다. 같은 "AI agent"라는 이름을 붙였더라도 필요한 안전 장치는 다릅니다. Chat agent에는 컨텍스트 표시와 tool confirmation이 중요할 수 있습니다. Browser agent에는 origin isolation, request signing, web conduct policy, credential scoping이 중요합니다. Enterprise agent에는 RBAC, audit log, approval state machine, rollback path, data retention policy가 더 중요합니다.
따라서 에이전트 안전을 하나의 체크박스로 다루면 안 됩니다. 제품 유형과 자율성 단계가 다르면 테스트해야 할 실패 모드도 달라집니다. Index가 의미 있는 이유는 이 차이를 한 표 안에 넣었기 때문입니다.
웹 행위에는 아직 표준이 없습니다
Index가 던지는 날카로운 문제 중 하나는 web conduct입니다. 공식 사이트는 에이전트가 웹에서 어떻게 행동해야 하는지에 대한 확립된 표준이 없다고 말합니다. 더 나아가 일부 에이전트는 anti-bot protection을 우회하고 인간 브라우징을 모방하도록 설계됐다고 지적합니다.
이 대목은 검색 크롤러 논쟁과 닮았지만 더 복잡합니다. 전통적인 크롤러는 robots.txt, user-agent, rate limit, IP 범위 같은 방식으로 어느 정도 식별되고 통제됩니다. 브라우저 에이전트는 사용자를 대신해 실제 브라우저 세션 안에서 움직일 수 있습니다. 사이트 입장에서는 이것이 사람인지, 사람의 지시를 받은 에이전트인지, 자동화된 대량 접근인지 구분하기 어렵습니다.
기업들은 종종 "에이전트는 사용자를 대신한다"고 설명합니다. 이 말에는 일리가 있습니다. 사용자가 직접 접속할 수 있는 사이트에서, 사용자를 대신해 정보를 읽고 양식을 작성하는 것은 접근성이나 생산성 측면에서 자연스러운 요구입니다. 하지만 사이트 운영자 입장에서는 그 행위가 사람이 직접 한 것인지, 에이전트가 대량으로 수행한 것인지, 승인된 범위를 넘었는지 확인하기 어렵습니다.
Index의 further details는 ChatGPT Agent만 cryptographic request signing을 사용한다고 설명합니다. 이 지표를 절대적 정답으로 볼 필요는 없습니다. 하지만 방향은 분명합니다. 에이전트가 웹에서 행동한다면 "나는 누구를 대신해 어떤 권한으로 접근한다"를 기술적으로 증명하는 장치가 필요합니다. 단순한 user-agent 문자열만으로는 부족합니다.
MCP 확산은 통제 문제를 더 크게 만듭니다
Index는 20/30 에이전트가 MCP를 지원한다고 정리합니다. Enterprise agent에서는 13개 중 12개가 MCP를 지원합니다. 이것은 에이전트 생태계가 빠르게 도구 호출 표준으로 수렴하고 있다는 신호입니다. 동시에 통제 문제를 더 크게 만듭니다.
MCP는 에이전트에게 데이터와 행동 표면을 열어줍니다. GitHub, Slack, Notion, 데이터베이스, 브라우저, 결제, 내부 API가 에이전트의 toolset이 됩니다. 이 자체는 좋은 방향입니다. 임의의 스크래핑이나 깨지기 쉬운 UI 조작보다, 명시적 도구 인터페이스가 있는 편이 더 낫습니다.
문제는 도구 수가 늘수록 평가 범위도 늘어난다는 점입니다. 같은 모델이라도 어떤 MCP 서버가 붙었는지, 어떤 credential이 들어갔는지, 어떤 approval policy가 적용됐는지에 따라 위험 수준이 달라집니다. 개발 환경에서는 파일 수정 정도였던 에이전트가, 엔터프라이즈 환경에서는 고객 데이터 조회, CRM 업데이트, 결제 워크플로, 클라우드 리소스 생성까지 이어질 수 있습니다.
이 때문에 "모델 제공자가 안전 평가를 했다"는 문장만으로는 부족합니다. 실제 배포 환경에서 에이전트가 어떤 도구를 쓸 수 있는지, 도구별로 어떤 권한과 승인 조건이 있는지, 각 호출이 어떤 로그로 남는지, 실패 시 롤백 가능한지까지 봐야 합니다. Index가 말하는 multi-layered ecosystem의 핵심이 바로 여기에 있습니다.
책임은 모델과 제품 사이에서 흩어집니다
AI Agent Index는 대부분의 에이전트가 GPT, Claude, Gemini 계열에 의존한다고 봅니다. 자체 모델을 쓰는 곳은 frontier lab과 중국 개발사 일부입니다. 동시에 23/30은 product level에서 fully closed source입니다. 즉 많은 에이전트는 닫힌 모델 위에 닫힌 에이전트 제품을 얹고, 다시 외부 도구와 기업 데이터에 연결되는 구조입니다.
이 구조에서 사고가 나면 책임 경계가 흐려집니다. 모델이 잘못 판단했을 수 있습니다. 에이전트 planner가 잘못된 subtask를 만들었을 수 있습니다. tool schema가 애매했을 수 있습니다. MCP 서버가 위험한 권한을 열었을 수 있습니다. 배포 조직이 approval policy를 느슨하게 설정했을 수 있습니다. 로그가 충분하지 않아 원인을 재구성할 수 없을 수도 있습니다.
Index의 중요한 기여는 이 책임 분산을 숫자로 보이게 만든 점입니다. 45개 필드는 단순 정보 수집이 아니라, 사고 조사와 조달 심사에서 물어야 할 질문 목록에 가깝습니다. 예를 들어 component accessibility, model specification, observation space, action space, memory architecture, user approval requirements, execution monitoring, emergency stop, web conduct, sandboxing, internal safety evaluations, third-party testing, vulnerability disclosure 같은 항목은 제품 소개 페이지보다 보안 설계 문서에 더 가깝습니다.
개발팀이 에이전트 도입을 검토한다면 이 필드를 그대로 체크리스트로 바꿀 수 있습니다. 공급사에 "SOC 2가 있습니까"만 묻는 것으로는 부족합니다. "에이전트별 internal safety evaluation이 있습니까", "agentic setup 전체를 평가했습니까", "도구 호출 로그를 고객이 보관하고 export할 수 있습니까", "agent identity와 human identity를 분리합니까", "emergency stop은 실행 중 어떤 상태까지 되돌립니까"를 물어야 합니다.
공개되지 않았다는 말과 존재하지 않는다는 말은 다릅니다
다만 Index를 읽을 때 조심해야 할 부분도 있습니다. 공개 정보가 없다는 것은 해당 기업이 아무런 안전 조치를 하지 않았다는 뜻이 아닙니다. 특히 enterprise platform은 고객 계약, 보안 문서, 비공개 audit, compliance portal 안에 더 많은 정보를 둘 수 있습니다. 중국 기업의 안전 문서가 적게 보인다는 지표도 실제 통제 부재와 공개 관행 차이를 구분해야 합니다.
Index 자체도 이를 인식합니다. 공개 정보, 데모, 문서, 논문, governance document, 개발자 correspondence를 기반으로 작성됐고, 실험적 테스트를 수행한 것은 아닙니다. 회사들은 4주 동안 주석 수정을 요청받았지만, 출판 시점 기준 응답률은 23%였고 substantive comment를 준 곳은 4/30이었다고 further details는 설명합니다.
따라서 이 자료를 "안전하지 않은 제품 목록"으로 읽으면 안 됩니다. 더 정확한 해석은 "외부인이 검증할 수 있는 안전 정보의 지도"입니다. 지도에 빈칸이 많다는 사실 자체가 뉴스입니다. 기업 고객, 정책 담당자, 개발자, 보안팀은 그 빈칸을 조달 질문으로 바꿔야 합니다.
개발자가 지금 바꿔야 할 질문
AI 에이전트 도입 논의는 종종 모델 성능 비교로 시작합니다. 어떤 모델이 SWE-bench를 잘 풀었는지, 어떤 에이전트가 브라우저 작업을 더 잘하는지, 어떤 도구가 더 빠른지입니다. 이 질문은 필요하지만 충분하지 않습니다. 에이전트가 실제 업무 시스템 안에 들어가면 성능보다 운영 증거가 더 중요해집니다.
첫째, 권한 모델을 물어야 합니다. 에이전트가 사람 계정을 빌려 쓰는지, 별도 machine identity를 갖는지, 도구별 최소 권한을 줄 수 있는지, 세션 단위 권한 제한이 가능한지 확인해야 합니다.
둘째, 로그와 재현성을 봐야 합니다. 에이전트가 어떤 observation을 읽고, 어떤 reasoning trace를 남기고, 어떤 tool call을 실행했으며, 어떤 승인 상태를 통과했는지 나중에 재구성할 수 있어야 합니다. "AI가 그렇게 했다"는 운영 답변이 아닙니다.
셋째, 평가 범위를 확인해야 합니다. base model evaluation과 agentic system evaluation은 다릅니다. 브라우저, 파일, 코드 실행, 사내 API, 결제, CRM, 장기 메모리가 붙은 상태에서 어떤 실패 모드를 테스트했는지 물어야 합니다.
넷째, 웹 행위 기준을 정해야 합니다. 브라우저 에이전트가 외부 웹을 탐색한다면 식별, rate limit, robots.txt, 봇 차단 우회, 사용자 동의, 결제 확인, 민감 정보 입력 정책이 필요합니다.
다섯째, 중단과 롤백을 상태 기계로 설계해야 합니다. human-in-the-loop라는 말만으로는 부족합니다. 누가 언제 승인하고, timeout이면 어떻게 되고, 승인자가 바뀌면 무엇을 기록하고, 외부 시스템 변경 이후 실패하면 무엇을 되돌릴 수 있는지 정의해야 합니다.
에이전트 시대의 조달 기준
AI Agent Index는 새 모델 발표처럼 화려하지 않습니다. 하지만 개발자와 플랫폼팀에게는 더 오래 남을 수 있는 자료입니다. 모델 성능은 몇 주마다 바뀝니다. 반면 에이전트 조달 기준, 로그 스키마, 승인 정책, 웹 행위 규범, 제3자 평가 요구는 조직의 운영 체계로 남습니다.
최근 에이전트 시장의 방향은 분명합니다. 코딩 에이전트는 PR과 CI로 들어가고, 업무 에이전트는 CRM과 ERP와 티켓 시스템으로 들어가고, 브라우저 에이전트는 웹 표면을 직접 움직입니다. 이 흐름을 멈추기는 어렵습니다. 그렇다면 질문은 "에이전트를 쓸 것인가"에서 "어떤 증거를 요구하고 어떤 권한으로 실행할 것인가"로 바뀝니다.
Index가 보여주는 25/30이라는 숫자는 경고에 가깝습니다. 에이전트 제품이 안전하지 않다는 단정이 아니라, 안전을 판단할 공개 증거가 아직 부족하다는 경고입니다. 자율성이 높아질수록 이 차이는 더 중요해집니다. 챗봇의 틀린 답변은 수정할 수 있지만, 에이전트의 잘못된 행동은 시스템 상태를 바꿀 수 있기 때문입니다.
결국 AI 에이전트의 다음 경쟁은 데모 영상보다 문서에서 갈릴 가능성이 큽니다. 어떤 회사가 더 많은 도구를 붙였는가보다, 어떤 회사가 권한과 감사와 평가를 더 명확히 공개하는가가 중요해집니다. 개발자와 기업 고객도 그 방향으로 질문을 바꿔야 합니다. 이제 에이전트의 능력을 묻는 것만으로는 부족합니다. 그 능력이 어떤 책임 구조 안에서 실행되는지 물어야 합니다.