agentmemory 0.9.21, 코딩 에이전트 기억의 공유층
agentmemory는 Claude Code, Codex, Cursor가 같은 로컬 메모리를 공유하는 방향으로 코딩 에이전트의 세션 단절 문제를 겨냥합니다.

- 무슨 일:
agentmemory가 5월 19일v0.9.21에서 OpenCode 플러그인과 22개 자동 캡처 hook을 추가했습니다.- GitHub API 기준 저장소는 5월 22일 마지막 push, 16.7k stars, Apache-2.0 상태입니다.
- 의미: 코딩 에이전트의 기억이
CLAUDE.md같은 정적 파일에서 공유 가능한 로컬 런타임으로 이동하고 있습니다. - 핵심 수치: 공개 benchmark에서 hybrid 검색은 15개 질의 기준 top-5 hit rate 100%, P@5 0.578을 냈습니다.
- 같은 corpus의 grep baseline은 P@5 0.267로, recall은 비슷했지만 noise가 더 많았습니다.
- 주의점: 지속 기억은 생산성을 높일 수 있지만, 오래된 결정과 민감 정보까지 오래 남기는 새 거버넌스 문제를 만듭니다.
코딩 에이전트가 실무 도구로 들어오면서 가장 반복적으로 드러나는 병목은 모델이 코드를 못 쓰는 순간만이 아닙니다. 오히려 꽤 평범한 문제가 계속 나타납니다. 어제 설명한 프로젝트 구조를 오늘 다시 설명해야 하고, 지난 세션에서 실패한 접근을 새 세션이 다시 시도하며, 팀이 정한 테스트 방식이나 배포 제약을 매번 prompt에 복사해야 합니다. 에이전트가 점점 길고 복잡한 작업을 맡을수록 이 단절은 더 비싸집니다.
agentmemory는 이 단절을 정면으로 겨냥하는 오픈소스 프로젝트입니다. 겉으로는 "AI 코딩 에이전트용 persistent memory"입니다. 하지만 흥미로운 지점은 단순한 노트 앱이 아니라는 데 있습니다. README는 Claude Code, Codex CLI, Cursor, Gemini CLI, OpenCode, Cline, Goose, Aider 같은 여러 도구가 같은 로컬 메모리 서버를 공유할 수 있다고 설명합니다. 한 에이전트가 남긴 세션 흔적을 다른 에이전트가 MCP나 REST를 통해 검색할 수 있는 구조입니다.
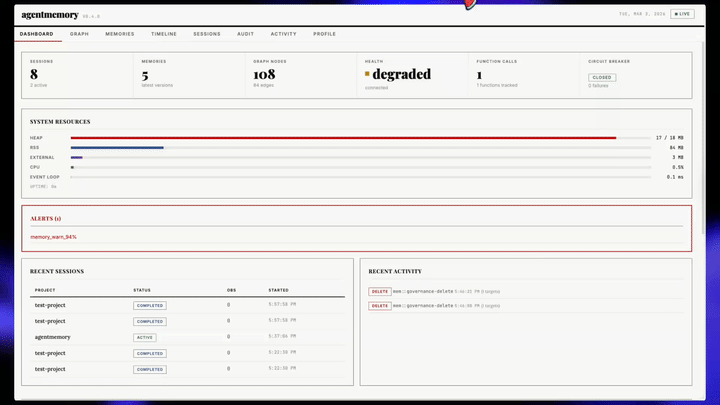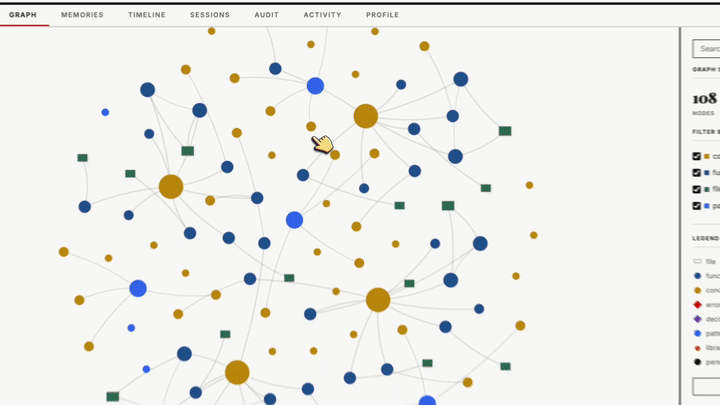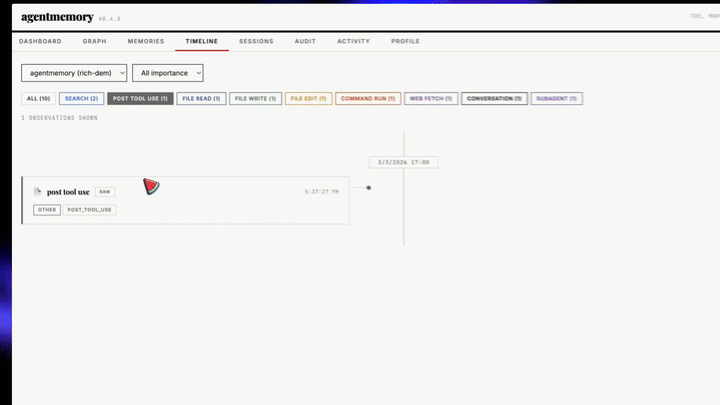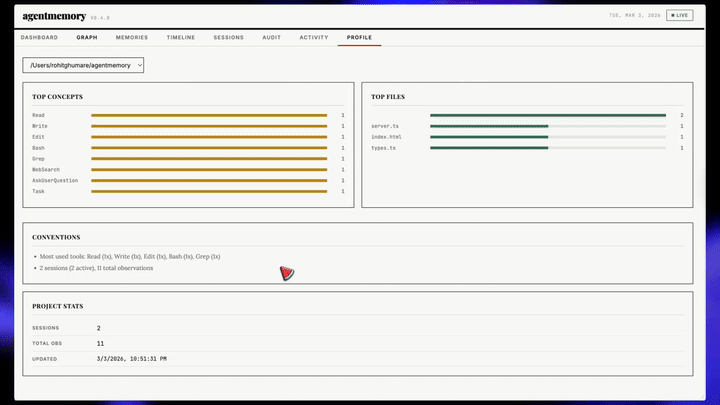
이번 뉴스의 계기는 2026년 5월 19일 공개된 v0.9.21 changelog입니다. 이 릴리스는 OpenCode 플러그인을 추가하고, session lifecycle, message, tool lifecycle, permission, task tracking을 포함한 22개 auto-capture hook을 붙였습니다. 동시에 MCP memory_recall의 파라미터 전달, CJK IME 검색 입력, 큰 세션 chunking, 대형 corpus의 index rebuild 같은 실사용 bugfix도 묶었습니다. 즉 제품 페이지의 큰 숫자보다 중요한 것은 "에이전트 메모리"가 실제 hook, 검색, viewer, config, upgrade 문제를 만나는 단계에 들어갔다는 점입니다.
세션 메모는 왜 다시 제품 문제가 됐나
초기 코딩 보조 도구에서 메모리는 그렇게 큰 문제가 아니었습니다. 한 파일을 고치거나 함수 하나를 작성하는 수준에서는 prompt 안에 충분한 정보를 넣을 수 있었습니다. 에이전트가 틀리면 바로 옆에서 사람이 고치면 됐고, 다음 세션으로 이어지는 상태도 많지 않았습니다. 하지만 지금의 코딩 에이전트는 repository를 훑고, test를 돌리고, branch를 만들고, PR 설명을 쓰고, 때로는 여러 시간 뒤에 다시 이어받습니다. 이때 기억은 편의 기능이 아니라 작업 연속성의 조건이 됩니다.
기존 방식은 대부분 파일 중심이었습니다. Claude Code에는 프로젝트 지시문과 memory 파일이 있고, Cursor에는 notepad나 rules가 있으며, Cline 계열에는 memory bank가 있습니다. 이런 방식은 단순하고 검토하기 쉽습니다. 사람이 직접 읽고 고칠 수 있기 때문입니다. 그러나 정적 파일은 시간이 지나면 stale해지고, 에이전트별 포맷으로 갈라지며, 세션 중 발생한 작은 결정과 실패를 자동으로 모으기 어렵습니다. 무엇을 넣을지 사람이 계속 판단해야 하는 것도 비용입니다.
agentmemory의 접근은 반대쪽에 가깝습니다. README는 매 tool use, prompt, stop 같은 lifecycle event를 hook으로 캡처하고, 이를 검색 가능한 memory로 압축한 뒤, 다음 세션 시작 시 필요한 context를 주입한다고 설명합니다. 핵심은 "사람이 정리한 메모"가 아니라 "에이전트 작업 로그에서 추출된 운영 기억"입니다. 이 차이는 작지 않습니다. 에이전트가 무엇을 했는지, 어떤 파일을 건드렸는지, 어떤 test가 실패했는지, 어떤 결정을 반복해서 내렸는지를 memory pipeline이 다루기 시작하기 때문입니다.
v0.9.21의 신호는 OpenCode보다 hook parity입니다
v0.9.21의 headline은 OpenCode 플러그인입니다. 하지만 더 넓게 보면 이 릴리스의 신호는 "agent별 hook surface를 맞춰 가는 작업"입니다. Claude Code와 Codex, OpenCode는 모두 세션과 도구 호출을 다루지만 event 이름, lifecycle 경계, plugin dispatch 방식이 다릅니다. agentmemory changelog에는 Codex Desktop의 plugin-local hook이 아직 dispatch되지 않는 문제와, 이를 global ~/.codex/hooks.json에 mirror하는 workaround까지 적혀 있습니다.
이 세부가 중요합니다. 에이전트 메모리는 모델 API만 붙인다고 작동하지 않습니다. 언제 세션이 시작됐는지, 사용자 prompt가 언제 들어왔는지, tool call 전후 payload를 어떻게 받을지, stop event가 정말 세션 종료인지 아니면 assistant turn 사이의 경계인지 알아야 합니다. 실제로 v0.9.20은 Codex Stop hook을 session-end로 연결했던 변경을 되돌렸습니다. Codex의 Stop이 전체 대화 종료 전에 여러 번 발생해 session을 너무 일찍 닫는 문제가 드러났기 때문입니다.
이런 종류의 bug는 에이전트 생태계가 아직 안정된 OS API처럼 굳지 않았다는 증거입니다. 각 도구는 빠르게 hook과 plugin을 추가하고 있지만, "세션", "중단", "작업 완료", "도구 실패" 같은 개념의 경계는 제품마다 다릅니다. 그래서 persistent memory는 단순 저장소보다 integration engineering에 가깝습니다. 누가 더 많은 vector DB 기능을 갖췄는가보다, 어느 에이전트의 lifecycle을 얼마나 정확히 읽는가가 품질을 좌우합니다.
벤치마크는 작은 corpus지만 질문은 정확합니다
agentmemory가 공개한 coding-agent-life-v1 scorecard는 작은 벤치마크입니다. 15개 fictional Claude Code session, 15개 hand-graded query, Rust CLI 프로젝트라는 제한된 설정입니다. 따라서 이 수치를 대규모 실무 성능으로 곧장 일반화하면 안 됩니다. 프로젝트 문서도 corpus가 빠른 iteration을 위한 작은 규모이며, paraphrased query와 longer multi-session chain 같은 hardening이 다음 목표라고 적습니다.
그럼에도 이 벤치마크가 유용한 이유는 질문의 형태가 실무적이기 때문입니다. "N+1 query fix가 어디 있었나", "4월 8일에 무엇을 shipped했나", "리뷰에서 나온 multi-session decision이 무엇인가" 같은 질문은 실제 코딩 에이전트가 다음 세션에서 필요한 기억에 가깝습니다. README가 제시하는 LongMemEval-S 수치보다, 이 작은 coding-agent corpus가 오히려 제품의 의도를 더 잘 보여줍니다.
공개 scorecard에서 agentmemory-hybrid는 top-5 hit rate 15/15, R@5 0.967, P@5 0.578, p50 latency 14ms를 냈습니다. 같은 corpus에서 grep baseline은 R@5가 0.967로 같았지만 P@5는 0.267이었습니다. 이것은 중요한 구분입니다. 단순 grep도 어딘가에는 답을 찾을 수 있습니다. 하지만 top-5가 noise로 절반쯤 채워지면 에이전트는 불필요한 context를 읽고 잘못된 연결을 만들 수 있습니다. 에이전트 메모리에서 recall만큼 중요한 것은 precision입니다.
기억은 context window 절약만의 문제가 아닙니다
agentmemory README는 token 절약도 강하게 내세웁니다. full context를 매번 붙이는 방식, LLM 요약 방식, agentmemory 방식의 연간 token cost를 비교하며 memory injection을 더 작게 만들 수 있다고 주장합니다. 이 주장은 직관적으로 맞습니다. 프로젝트의 모든 과거 대화를 매번 context window에 넣을 수는 없고, 요약만 누적하면 오래된 오류가 fossil처럼 남을 수 있습니다. 검색 기반 memory는 필요한 조각만 꺼내는 방향입니다.
하지만 코딩 에이전트의 기억은 token 절약보다 넓은 문제입니다. 첫째, 반복 실패를 줄입니다. "이 라이브러리는 Edge runtime 때문에 jsonwebtoken 대신 jose를 쓴다" 같은 결정은 단순한 배경지식이 아니라 잘못된 PR을 막는 제약입니다. 둘째, 팀의 선호를 보존합니다. test naming, migration policy, lint rule, release checklist는 모델이 일반 지식으로 알 수 없습니다. 셋째, accountability를 만듭니다. 어떤 세션이 어떤 commit을 만들었는지 연결되면, 나중에 사람이 변경의 원인을 추적할 수 있습니다.
실제로 changelog에는 session-to-commit linking도 등장합니다. full SHA를 key로 commit link record를 만들고, session에서 commit으로, commit에서 session으로 역조회할 수 있게 하는 구조입니다. 이것은 "기억"이라는 단어보다 감사 로그에 가깝습니다. 에이전트가 코드를 만든 뒤 문제가 생겼을 때, 우리는 어느 대화와 어떤 관찰이 그 변경으로 이어졌는지 알고 싶어집니다. 메모리 시스템은 생산성 도구이면서 동시에 forensic surface가 됩니다.
로컬 우선 설계가 주는 장점과 착시
agentmemory는 로컬 실행과 외부 DB 없음도 강조합니다. 기본 서버는 로컬에서 뜨고, viewer는 별도 port에서 memory build를 보여주며, SQLite와 iii-engine을 바탕으로 움직입니다. LLM-backed compression과 summarization도 기본으로 무조건 외부 API를 호출하는 것이 아니라, provider 설정이나 opt-in을 요구하는 방향으로 설명됩니다. 에이전트 작업 로그에는 코드, 파일 경로, 내부 설계, 때로는 secret 주변 맥락이 섞일 수 있으므로 로컬 우선은 설득력 있는 기본값입니다.
다만 로컬이라고 해서 자동으로 안전한 것은 아닙니다. 메모리 서버가 여러 에이전트에 공유되면 권한 경계가 새로 생깁니다. Claude Code가 남긴 기억을 Cursor가 읽어도 되는지, 개인 프로젝트 기억과 회사 repository 기억이 같은 store에 섞여도 되는지, remote deployment를 켰을 때 인증과 audit가 충분한지 따져야 합니다. README에는 governance delete, audit, secret 관련 설정이 보이지만, 사용자가 실제로 어떤 정책을 적용하는지는 별개의 문제입니다.
또 하나의 착시는 "기억이 많을수록 좋다"는 생각입니다. 에이전트에게 오래된 기억은 도움일 수도 있고 독일 수도 있습니다. 이미 폐기된 architecture decision, 임시 workaround, 한 번뿐인 실험 결과가 계속 recall되면 새 작업을 오염시킬 수 있습니다. agentmemory가 lifecycle, decay, auto-forget을 말하는 이유도 여기에 있습니다. 지속 기억의 품질은 저장 능력이 아니라 잊는 정책까지 포함합니다.
경쟁은 memory API와 agent harness 사이에서 벌어집니다
agentmemory의 경쟁 구도는 조금 복잡합니다. 한쪽에는 mem0, Letta/MemGPT, Khoj 같은 범용 memory layer가 있습니다. 이들은 agent memory를 API나 runtime 관점에서 다룹니다. 다른 한쪽에는 Claude Code, Cursor, Cline, Codex처럼 코딩 에이전트 자체에 들어간 memory 기능이 있습니다. agentmemory는 이 둘 사이에 서 있습니다. 범용 memory engine처럼 보이지만, 실제 hook과 plugin은 코딩 에이전트 lifecycle에 깊게 붙습니다.
이 위치는 장점과 위험을 동시에 줍니다. 장점은 에이전트 독립성입니다. 팀이 Claude Code와 Cursor, Codex를 함께 쓰면 같은 memory server를 두고 도구를 바꿔도 일부 연속성을 유지할 수 있습니다. 위험은 통합 부담입니다. 각 도구가 memory 기능을 내장하고, MCP와 hook 표준이 바뀌며, vendor가 자체 cloud memory를 밀기 시작하면 외부 memory runtime은 계속 adapter를 따라가야 합니다.
개발팀 입장에서 지금 중요한 질문은 "agentmemory를 당장 도입할 것인가"보다 "우리의 에이전트 기억은 어디에 있고 누가 관리하는가"입니다. 프로젝트 지시문 파일만으로 충분한 팀도 있을 것입니다. 보안상 모든 자동 캡처를 금지해야 하는 팀도 있을 수 있습니다. 반대로 여러 에이전트가 같은 repository에서 돌아가고, onboarding context가 길며, 반복 작업이 많은 팀은 memory runtime을 따로 평가할 이유가 생깁니다.
실무에서 확인해야 할 네 가지
첫째, capture 범위입니다. 어떤 prompt, tool payload, command output, file path가 저장되는지 확인해야 합니다. 특히 secret masking, .env, production log, 고객 데이터가 섞일 가능성을 봐야 합니다. 자동 캡처는 편하지만, 자동으로 위험한 정보도 잡습니다.
둘째, retrieval 품질입니다. 메모리 시스템은 "검색된다"가 아니라 "작업에 맞는 기억이 noise 없이 올라온다"로 평가해야 합니다. 공개 benchmark처럼 P@5, R@5, hit rate를 팀 내부 작업 로그에 맞춰 측정하는 편이 좋습니다. grep보다 낫다는 주장이 실제 repository에서도 유지되는지 봐야 합니다.
셋째, forget과 governance입니다. 오래된 decision을 어떻게 decay할지, 잘못 저장된 기억을 누가 지울 수 있는지, 삭제가 audit에 남는지 봐야 합니다. 에이전트 기억은 지식 베이스가 아니라 작업 상태의 일부이므로 정정 가능성이 중요합니다.
넷째, 에이전트 간 경계입니다. 한 memory server를 여러 에이전트와 여러 프로젝트가 공유할 때 namespace와 권한 모델이 필요합니다. 개인 도구처럼 쓰는 경우와 팀 도구로 배포하는 경우의 리스크는 다릅니다. "로컬이라 괜찮다"는 판단은 팀 공유와 remote deployment가 들어오는 순간 깨질 수 있습니다.
기억을 공유하는 순간 에이전트는 팀원이 됩니다
agentmemory 0.9.21은 거대한 플랫폼 출시라기보다 작은 오픈소스 프로젝트의 빠른 진화에 가깝습니다. corpus도 작고, 0.x 릴리스이며, 통합 표면도 계속 바뀝니다. 그래서 이 뉴스를 "이 도구가 표준이 된다"로 읽을 필요는 없습니다. 더 중요한 것은 코딩 에이전트 제품들이 공통으로 마주한 방향입니다. 세션이 길어지고, 도구가 많아지고, 사람이 여러 에이전트를 병렬로 쓰기 시작하면 기억은 UI 바깥의 인프라가 됩니다.
그 인프라는 단순한 벡터 검색이 아닙니다. hook 안정성, session boundary, commit link, audit log, forget policy, local-first storage, MCP surface, viewer, benchmark가 함께 필요합니다. agentmemory가 흥미로운 이유는 이 조각들을 한 저장소 안에서 실제로 부딪치고 있기 때문입니다. README의 큰 숫자를 모두 그대로 믿을 필요는 없지만, changelog의 작은 bugfix들은 오히려 더 설득력 있습니다. 여기에는 실제 에이전트 메모리 시스템을 운영할 때 마주치는 거친 경계가 드러납니다.
앞으로 코딩 에이전트 경쟁은 모델 성능과 IDE UX만으로 끝나지 않을 것입니다. 누가 더 좋은 context를 기억하고, 누가 오래된 context를 안전하게 잊고, 누가 여러 agent surface 사이에서 같은 작업 기억을 일관되게 전달하는지가 중요해집니다. agentmemory 0.9.21은 그 변화의 작은 표본입니다. 코딩 에이전트가 한 번 쓰고 닫는 assistant에서 장기 작업자에 가까워질수록, 기억은 기능이 아니라 운영층이 됩니다.